Make Embeddings Great Again with Self-supervised Learning
Bohua Peng
4 May 2021
content
- Preliminary 🤔
- Generative Methods 💚
- Handcrafted Pretext Training 💡
- Contrastive Learning 🕯️
- metric learning
- Loss functions
- Experiments 💻
- Future directions🌟
- Hard negative mining
- Decorrelating / Multiple ontological representations)
Preliminary
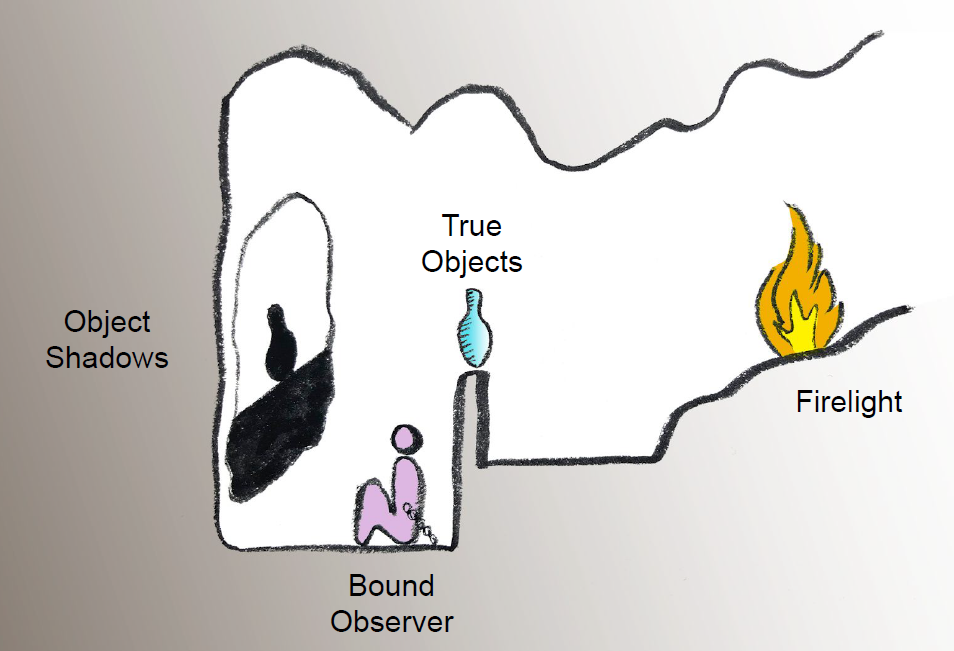
Plato’s allegory of the cave
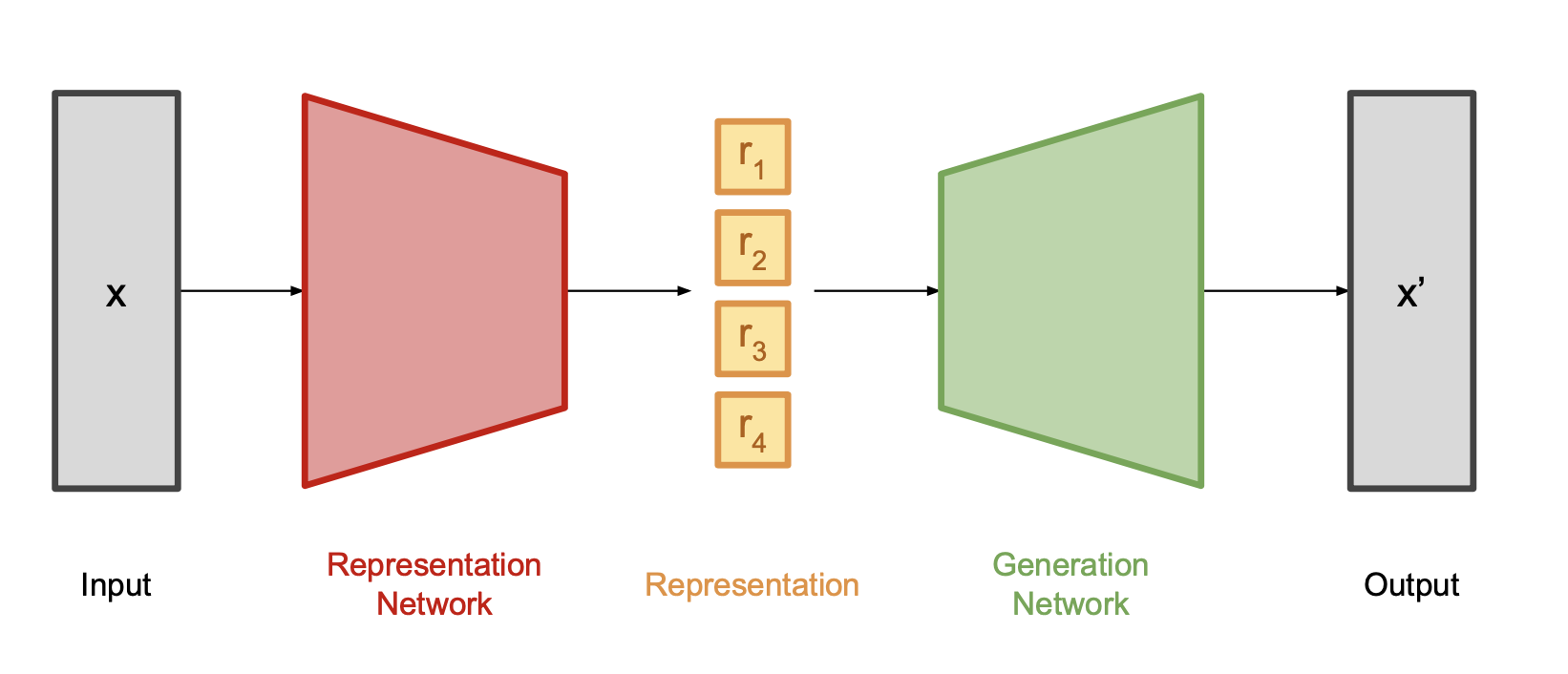
A lower-dimensional representation
Preliminary
Due to information loss ...
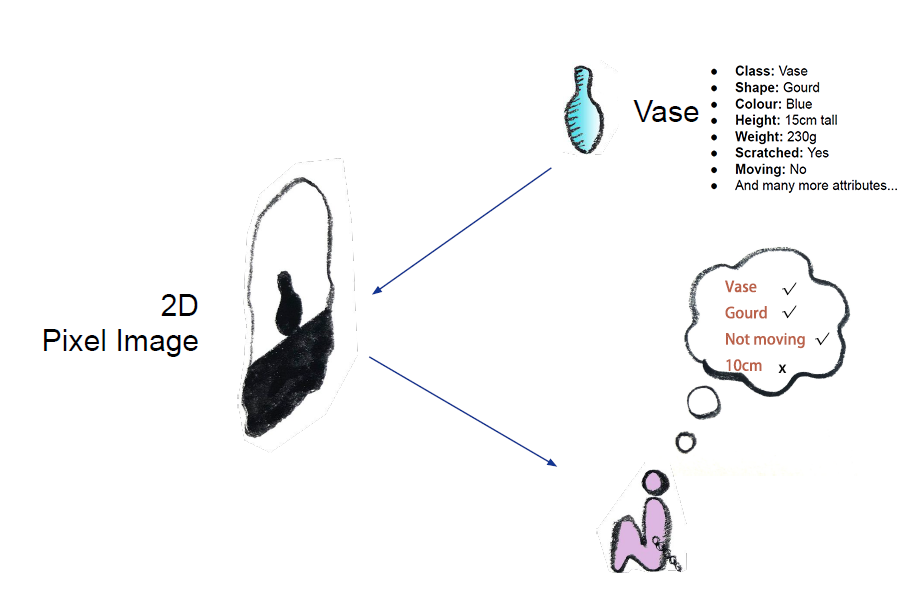
The same goes for deep representation learning
Embedding zoo

word embeddings
wave embeddings
face embeddings


Can we learn representations without human annotations?

Handcrafted pretext tasks

Learning from predicting a part of data with the rest
These methods are very flexible. However, they are not good enough ...
These heuristics are quite fragile. They need a set of carefully pre-defined configurations which are difficult but not too difficult, otherwise ...
Handcrafted pretext tasks
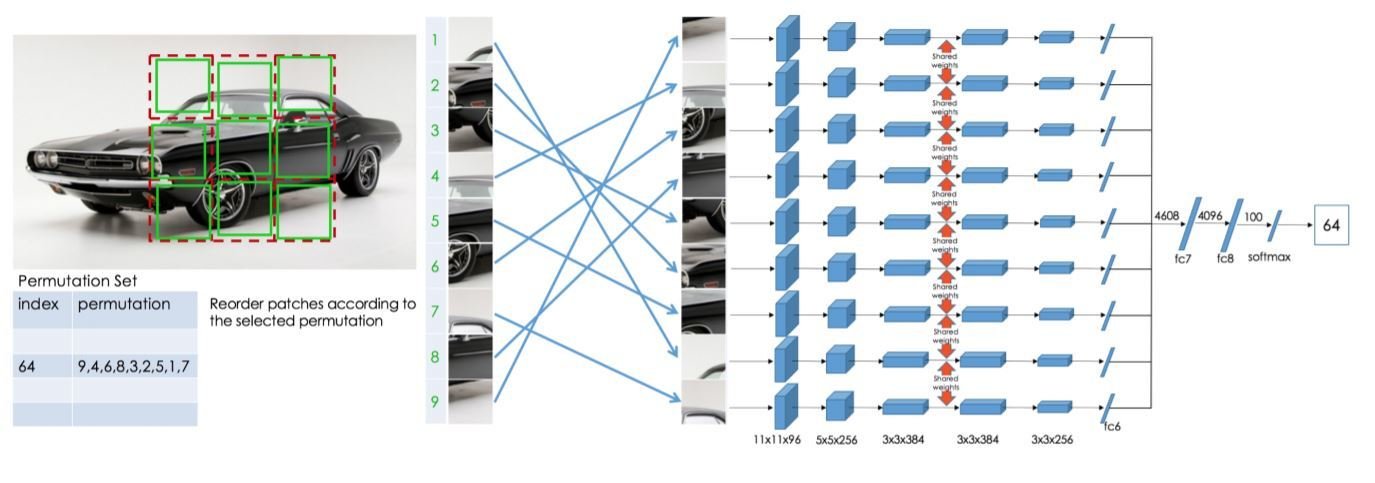
[1] Unsupervised Learning of Visual Representations by Solving Jigsaw Puzzles 2016
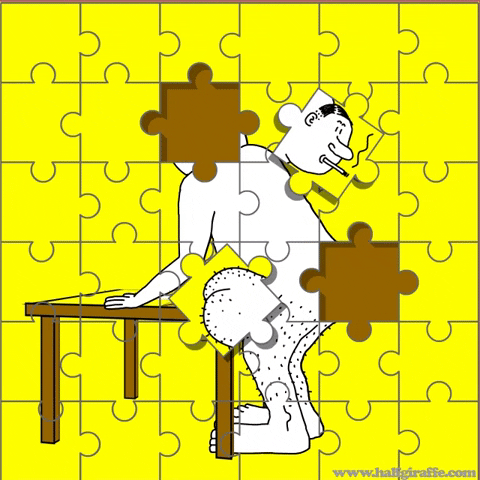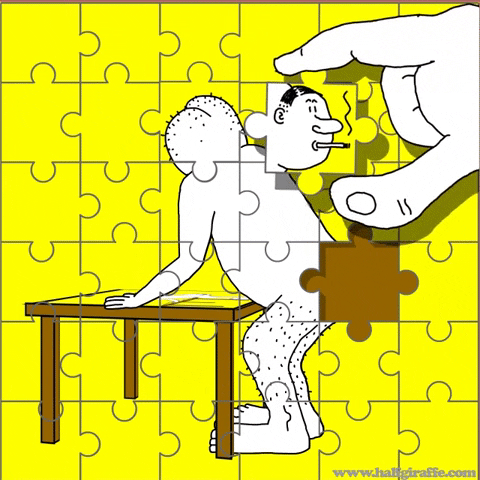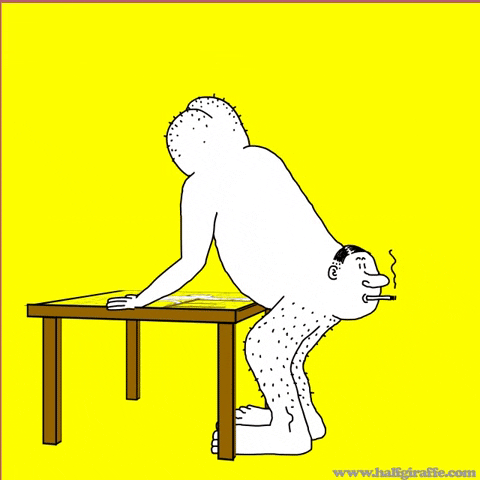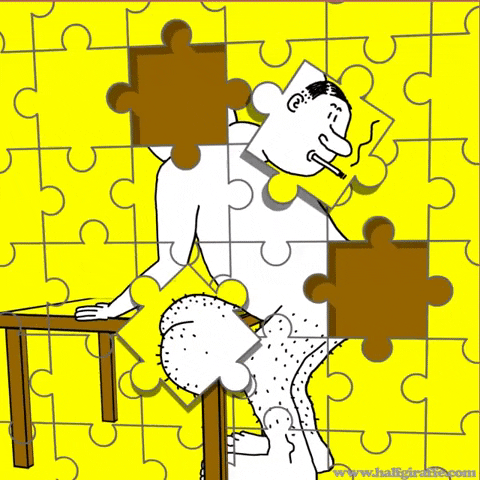
Generative methods
VAE
Learning by reconstructing
Limitations:
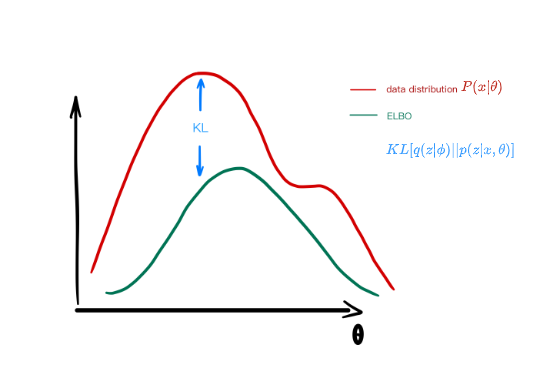
-
Posterior collapse
- constant representations
- noisy representations
- A hard trade-off between generality and fidelity
- disentangled representations
- variational inference backbone
Pros:
Generative methods
Learning by generating - GAN

Problems:
- mode collapse
- forgetfulness w.r.t discriminator
Self-Supervised GANs via Auxiliary Rotation Loss CVPR 2019
Adding pretext tasks to GAN

Text
Is there a more general proxy task to learn other than reconstruction , e.g., relational classification?
Can we not trade off generality and interpretability?
Pulling semantically
similar objects close to each other with a contrastive loss
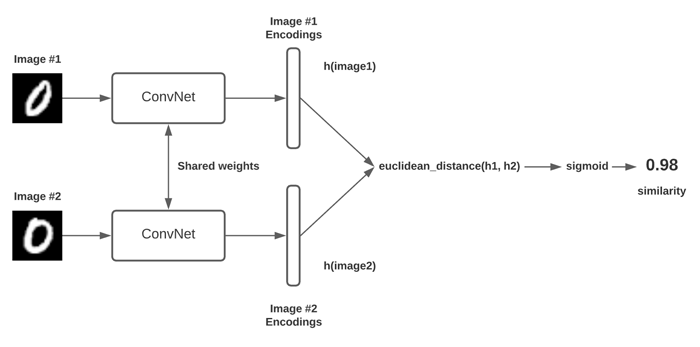
Metric learning
Learning by comparing
Let Y = 0, if anchor X1 and input image X2 are from the same person.
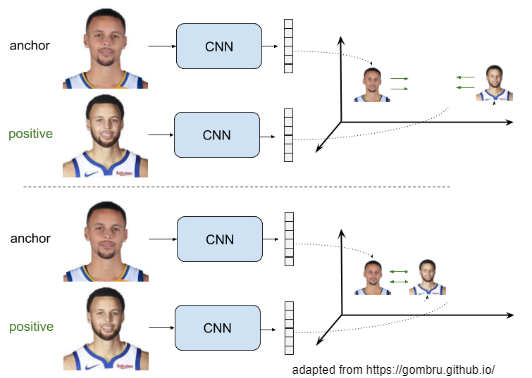

[2] Learning a Similarity Metric Discriminatively, with Application to Face Verification 2005
contrastive loss:
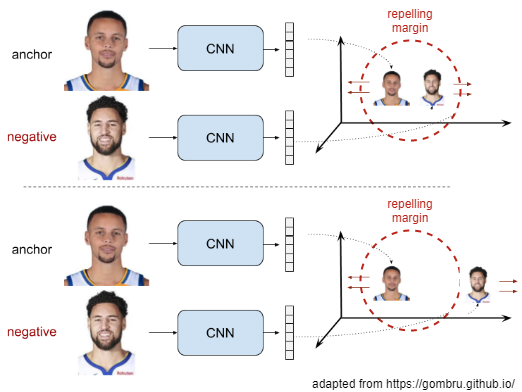
Pushing semantically
diverse objects away from each other with a contrastive loss
Metric learning
Let Y = 0, if anchor X1 and input image X2 are from different people.
https://keras.io/examples/vision/siamese_network/
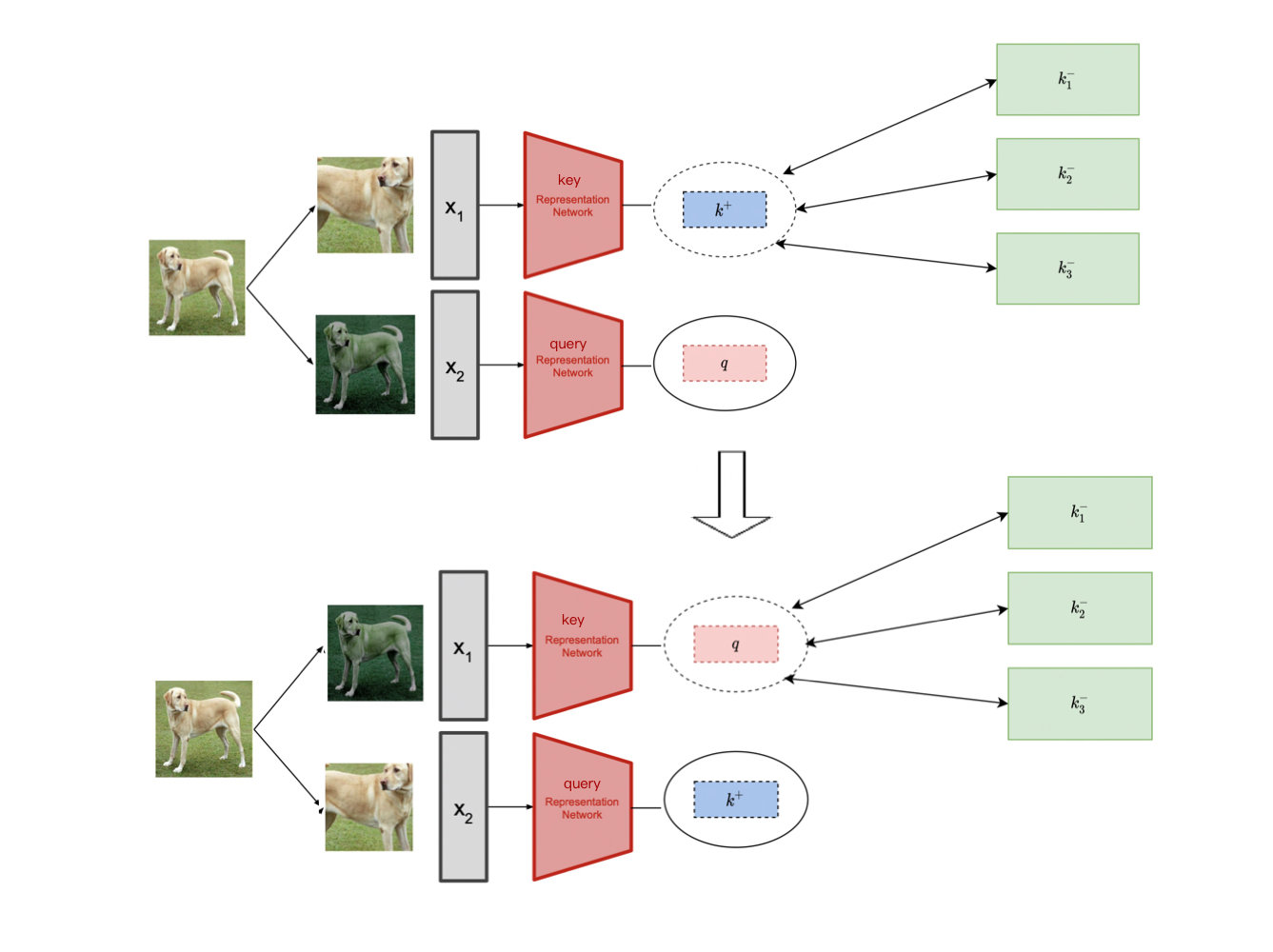
Unsupervised contrastive learning
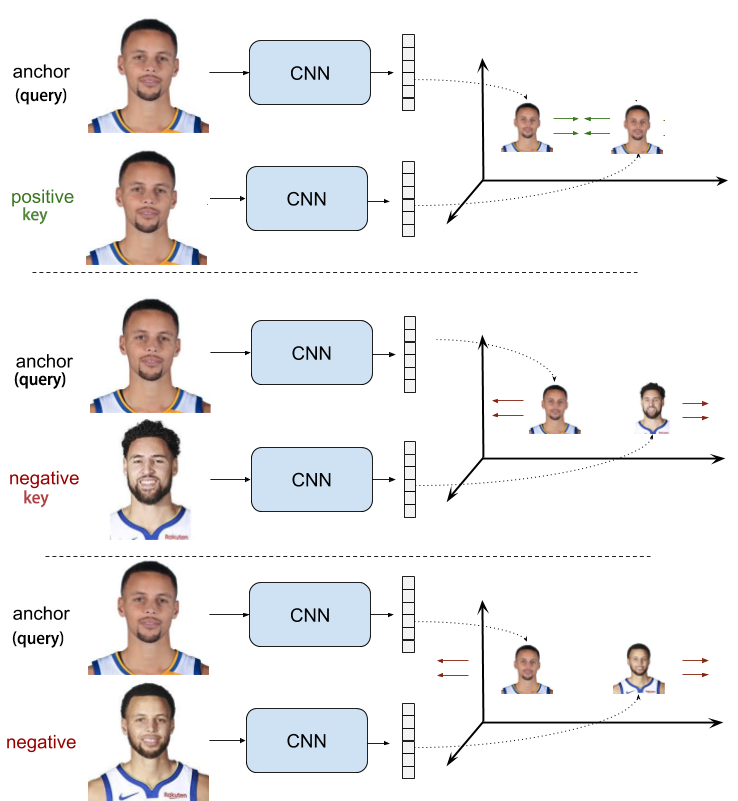
Consider views of the same images as positive keys while views of other images as negative keys
Instance level discrimination
🤔
However, it meets mode collapse


Modern contrastive learning
The successful story of SimCLR
- strong data augmentation
- a large number of negative samples
- nonlinear projection head (MLP)
- InfoNCE loss ( contrastive cross entropy)
SimCLR 2020
Loss function

Normalized temperature-scaled cosine similarity
Swapped-version loss to avoid mode collapse
InfoNCE
(contrastive cross entropy)
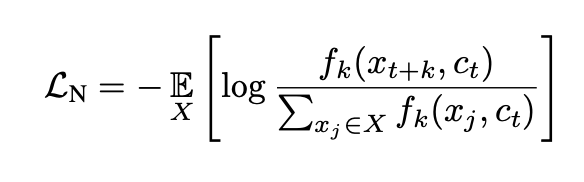
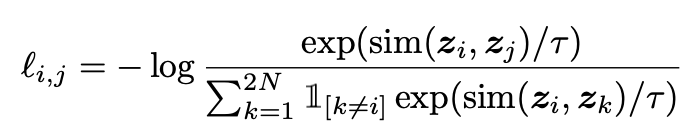
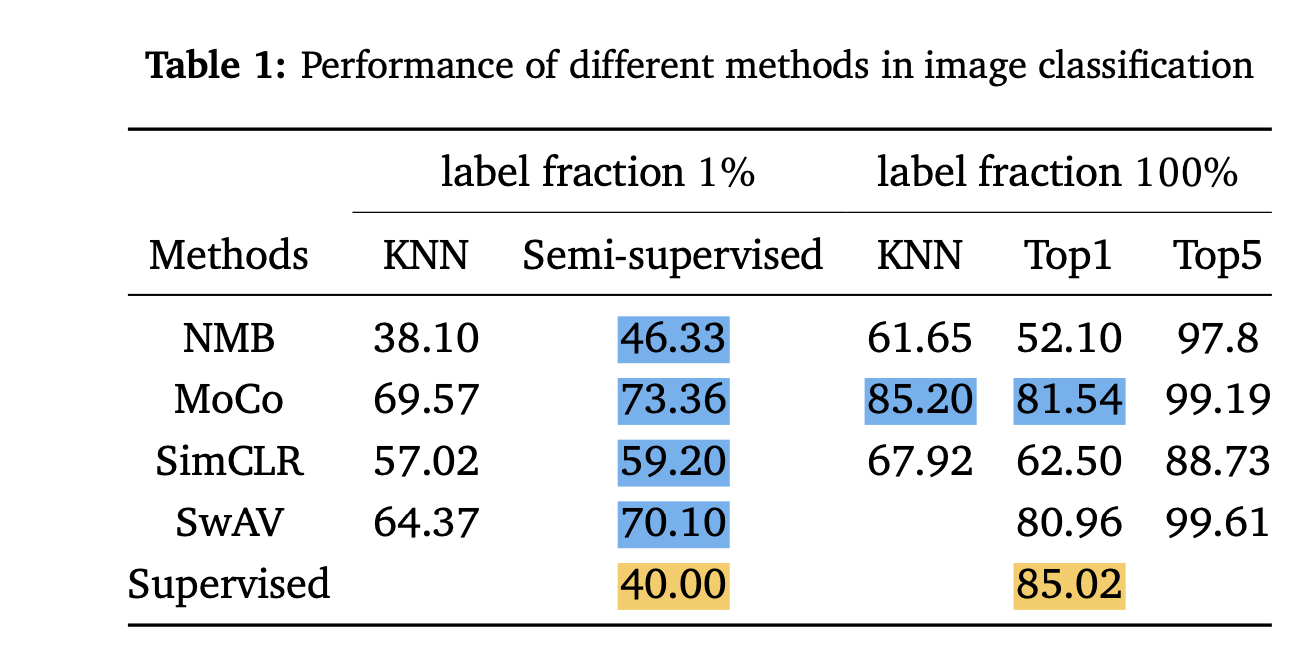
Experiments

Verify 4 contrastive methods pretrained on CIFAR10
T-SNE visualization of learned representations for CIFAR10
Same data augmentation:
random resized crop
color jittering
Linear evaluation protocol:
Augmentation and regularisation are not allowed when finetuning the linear projection head
Experiments
MoCo pretrained on histopathological dataset
T-SNE visualization of learned representations for CIFAR10



Learned feature maps
results
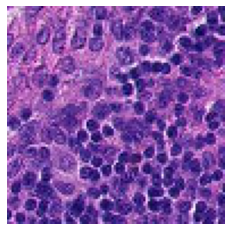
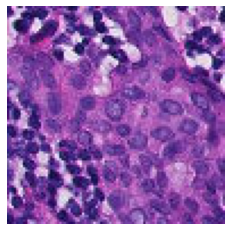
benovelent
malignant
Future directions🌟
"Hard" Negative Mining

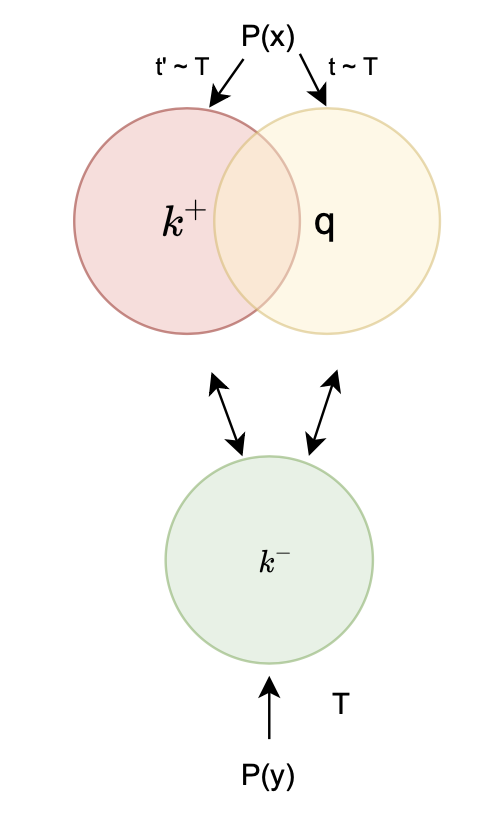
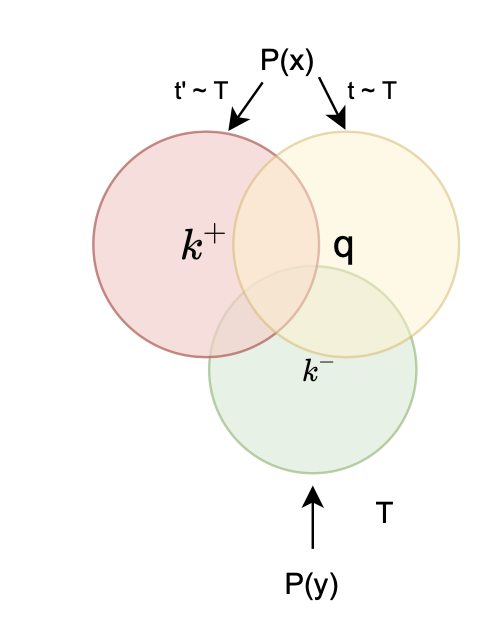
Relate to InfoMax
easy pair
hard pair
Future directions🌟
Negative samples might not be necessary
- Decorrelating information in the representations
- reduce redundant information between distorted views
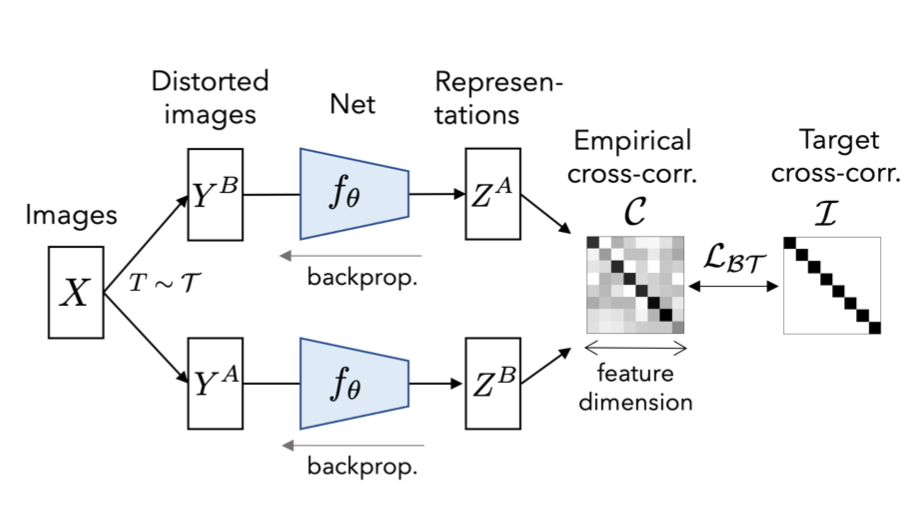
Barlow Tiwns