DeepCurl:
Explore Curriculum learning for Image classification
7 September
Bohua Peng

Background
Problem: Big data often come with noisy or ambiguous content. Learning in a random order leads to overfitting (memorizing) .
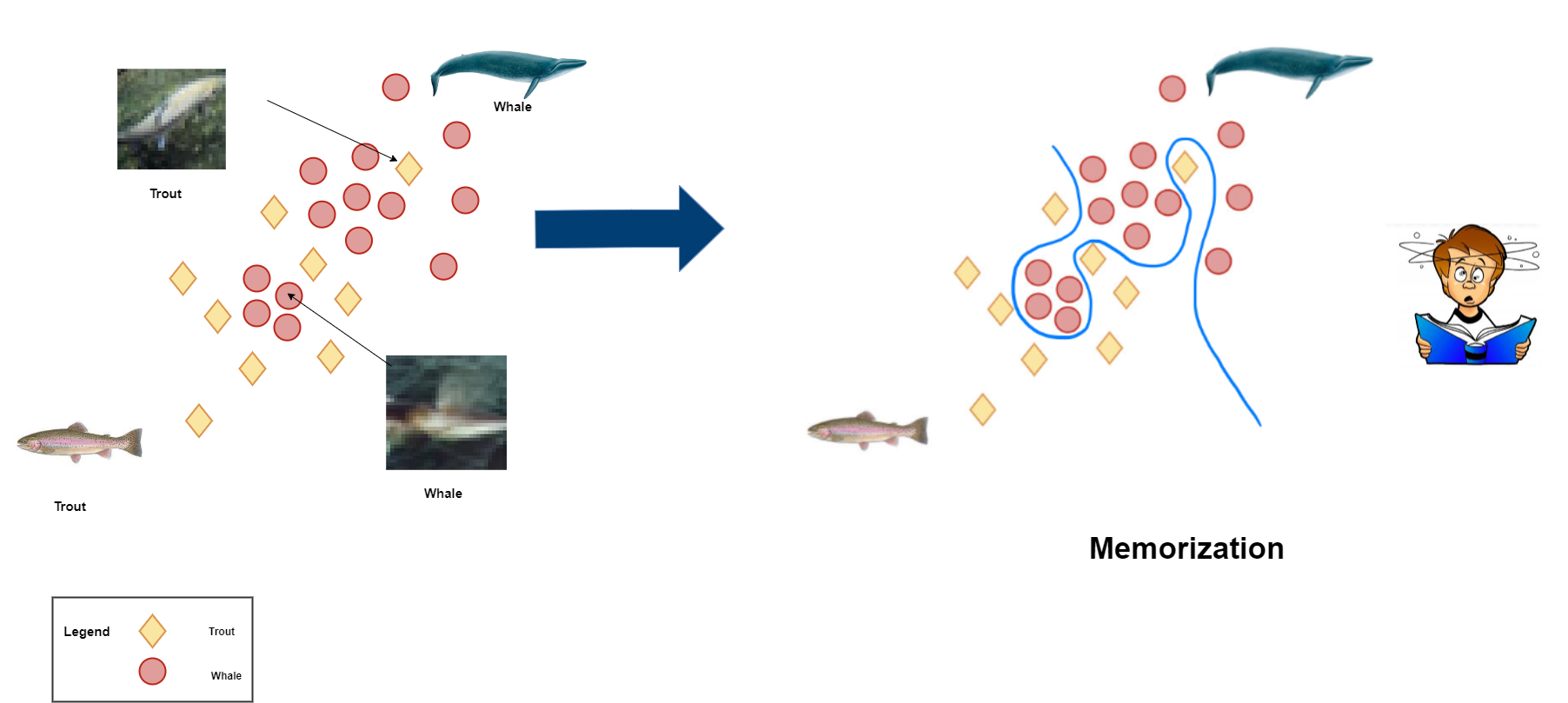
Can we improve generlization without changing the base ML method?
Human learners perform better when learning from easy to hard .[1][2]
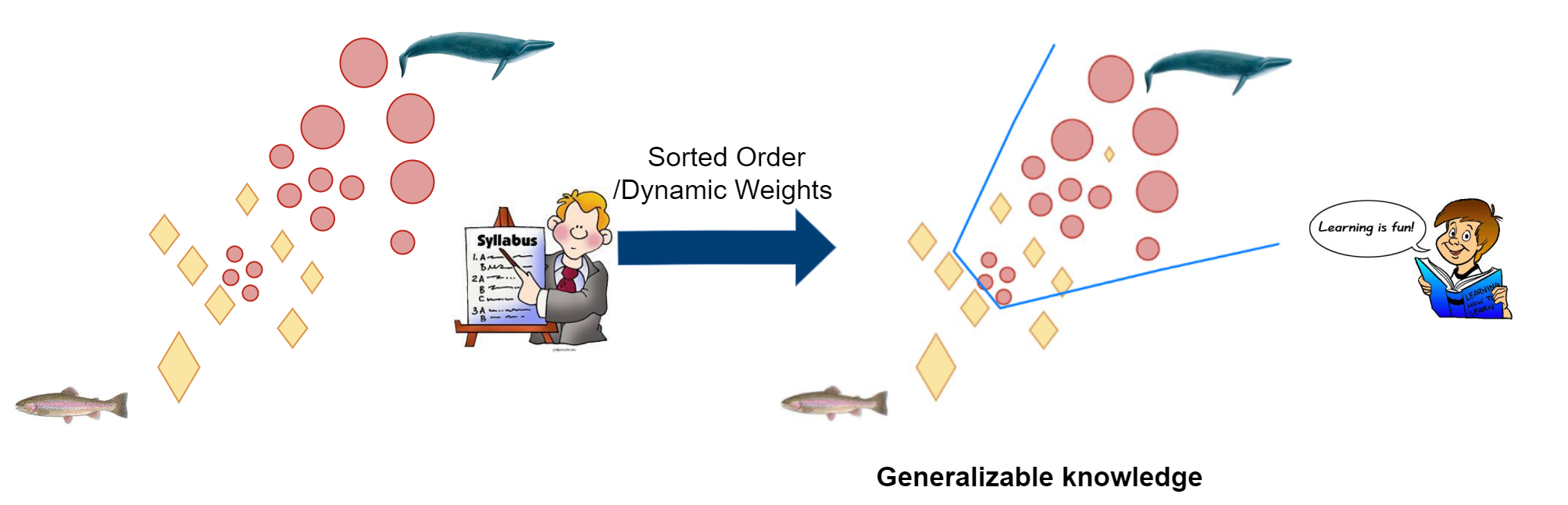
To improve generalization, we focus on instance-level curriculum learning in this project
Background
We answer two key questions about CL for image classfication:
How to define the difficulty of an image? scoring functioin?
When should we add in more difficult images? pacing function?
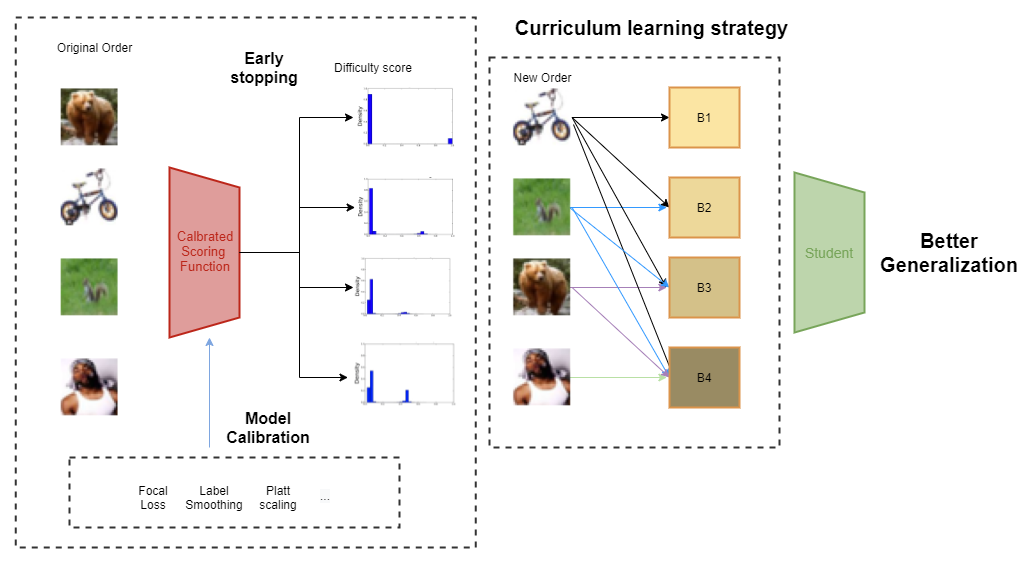
Difficulty measurement Calibration!
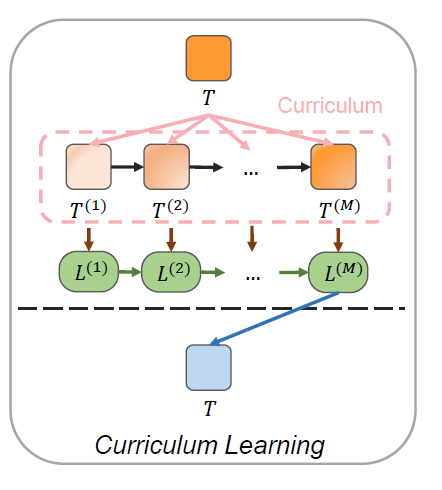
Part One
Part Two
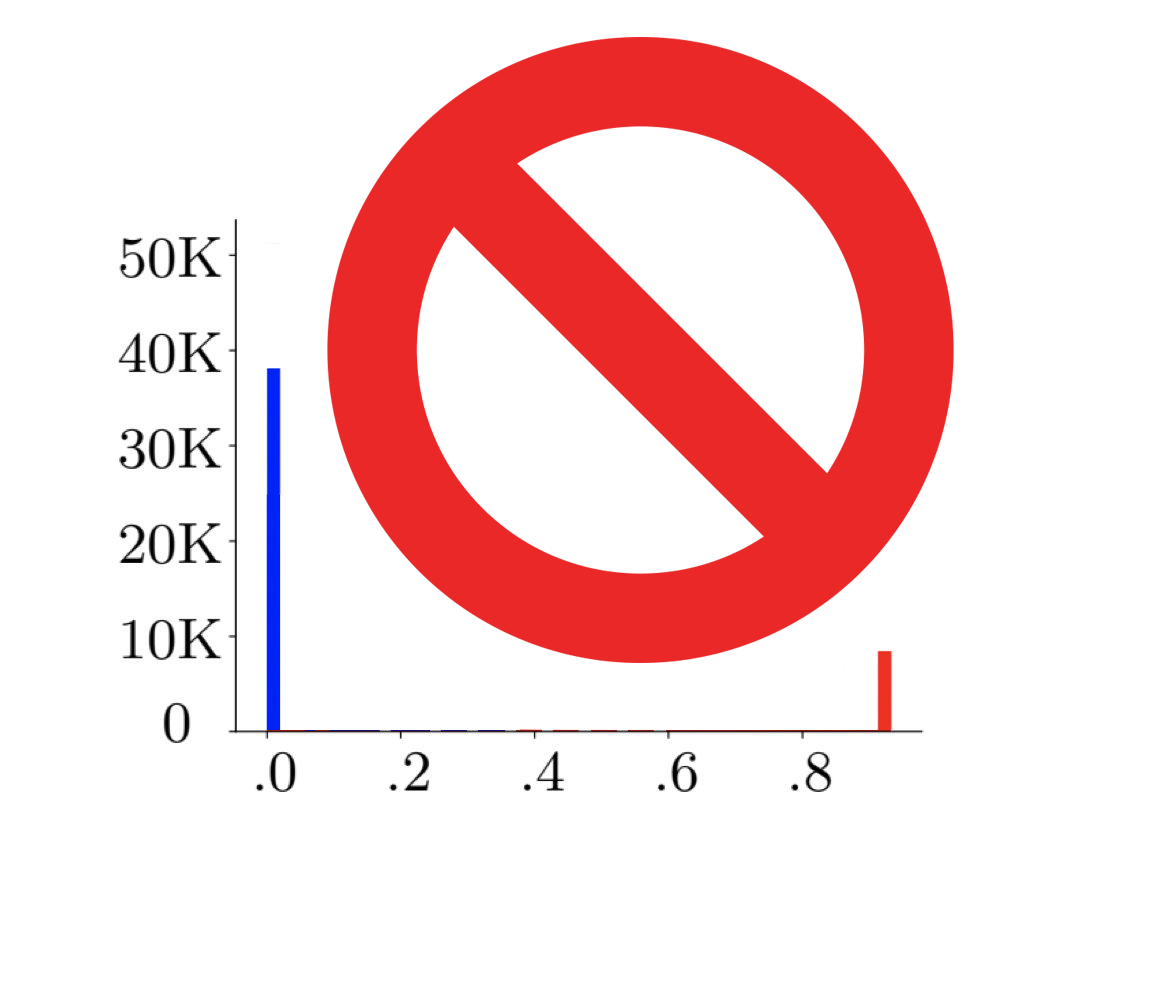
Distribution of fixed (precomputed) scores is binary
- Categorize existing difficulty scores
- A novel 2D difficulty metric - Prediction depth[3]
- Our highly interpretable difficulty metric - Angular gap
- Analyse correlation between existing difficulty metrics
Outlines:
How to define difficulty?
Part1: Instance-level difficulty metrics
Part2: Paced / Self-paced learning methods
- Paced learning - Our class-balance-aware (CBA) scheduler
- Self-paced learning (SPL) learns in a class imbalanced way
When should we add in more difficult samples?
Part One: Difficulty metrics
Part One: Difficulty metrics
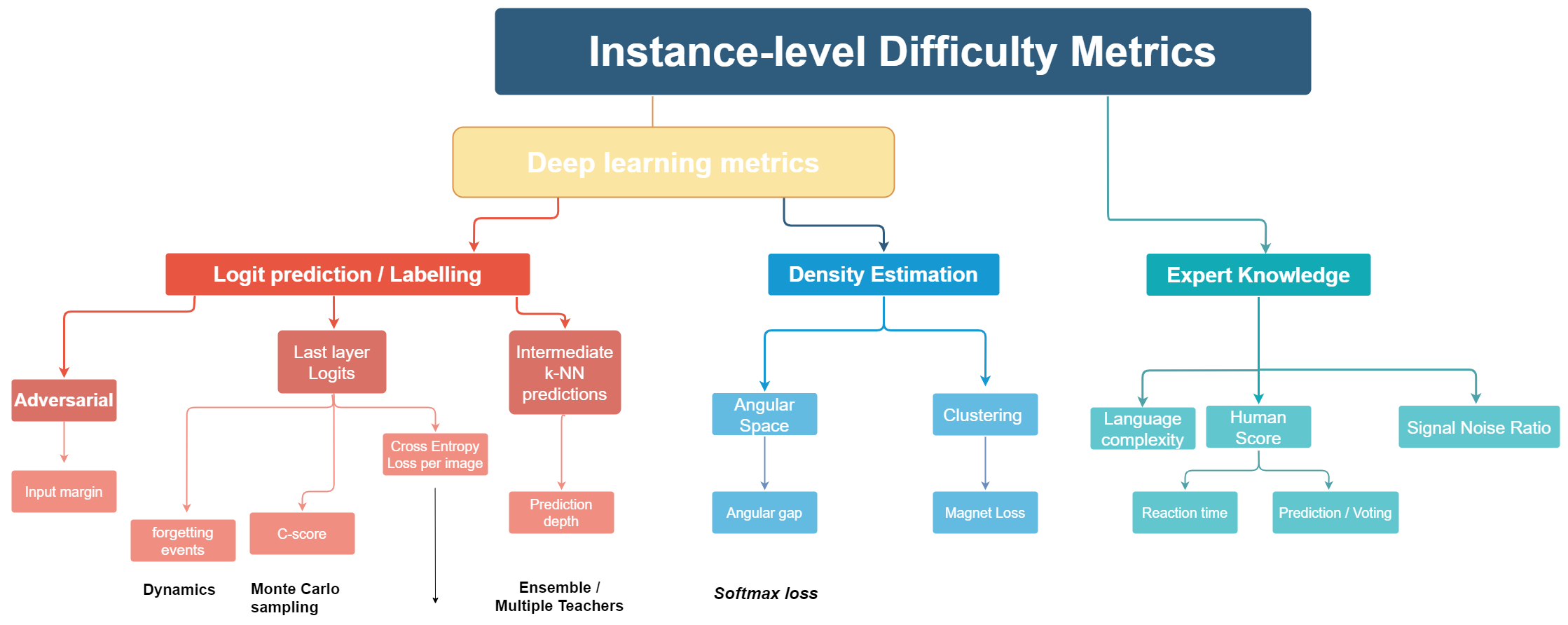
We focus on estimating instance-level difficulty score for image classification
Categorisation
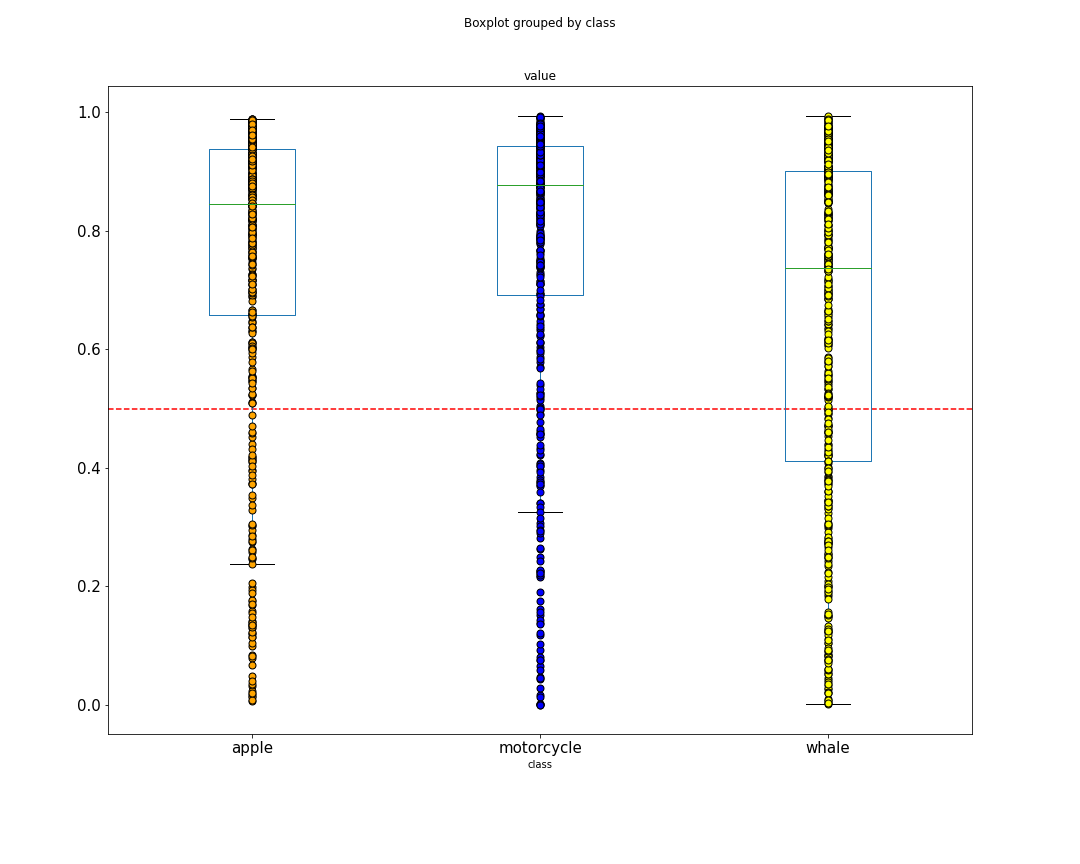
CIFAR10-H Dataset

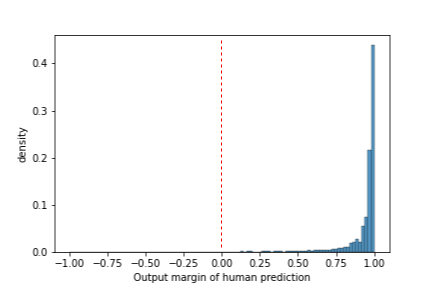
CIFAR10-H shows human uncertainty for image classification

Ambiguity: 79 examples are misclassified by annotators
uncalibrated

Gap between GT class and the second-largest logit
The distribution of output margins of samples
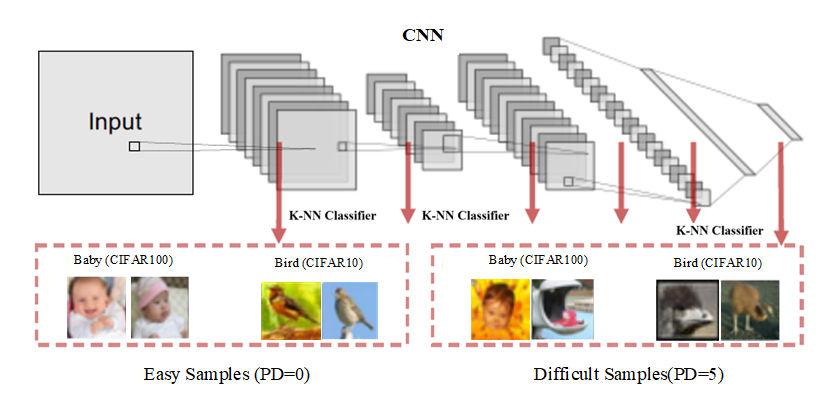
2D difficulty score: Prediction depth[3]
Prediction depth is the earliest layer where the subsequent k-NN predictions coverge.
temperature scaling
Generally, easy samples have lower prediction depth while difficult samples have larger prediction depth
Part One: Difficulty metrics
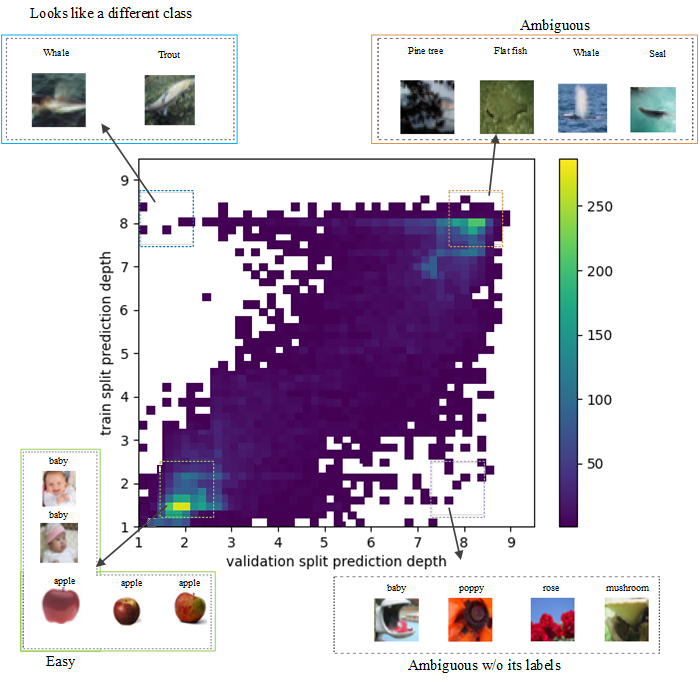
We measure two prediction depth scores for each example
Never learnt
Acc. about 0.01
Easily affected
by seeds
about 0.5
Informational
Acc. About 0.8
Easy
Acc. about 1.0
Part One: Difficulty metrics
(cut out the right amount of uncertainty)
A highly interpretable difficulty score - Angular Gap
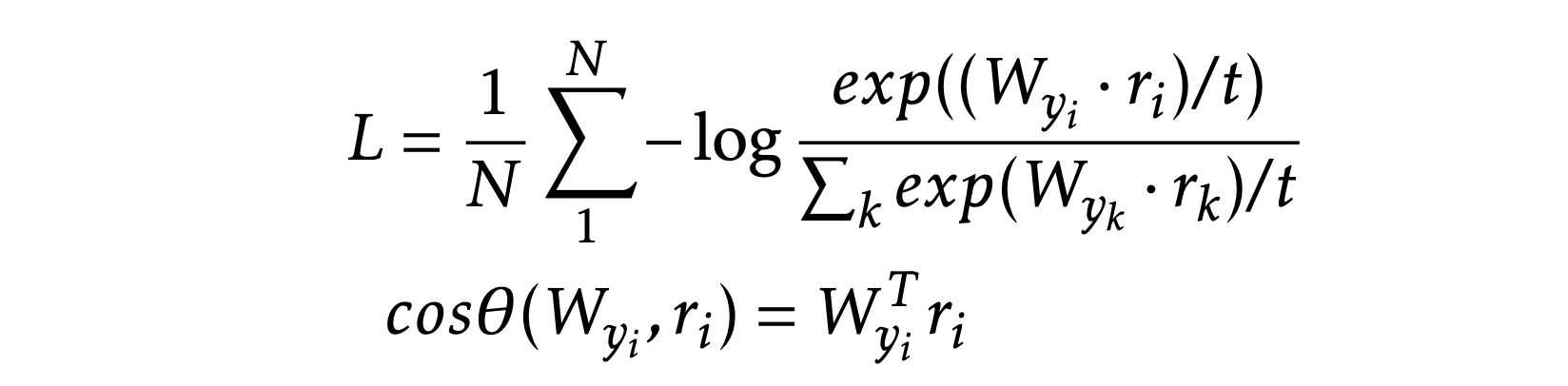
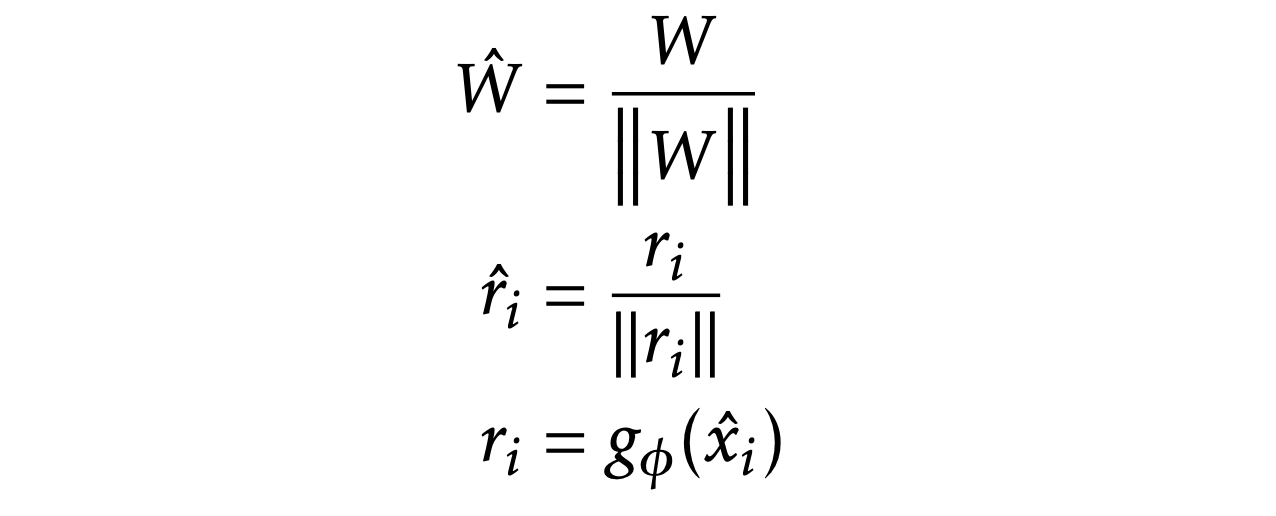
Base method:
Normalized softmax classifier
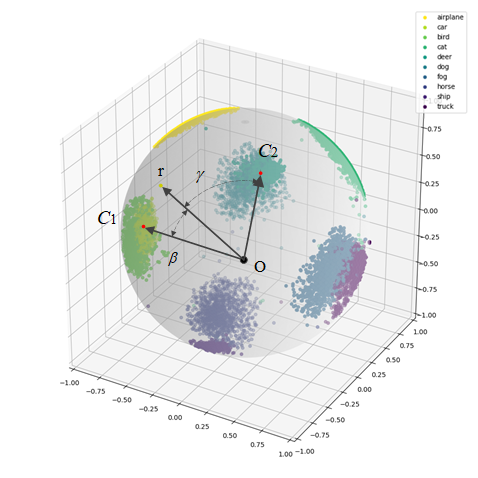
Angular gap is the gap between GT class and the second-largest cosine distance
Part One: Difficulty metrics
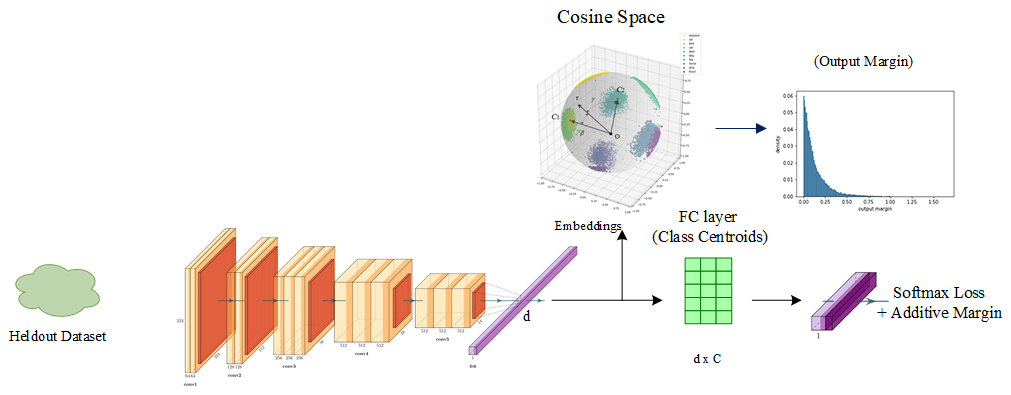
Stage one: Pretraining the teacher: Let the hyper ball converges
but not overfit
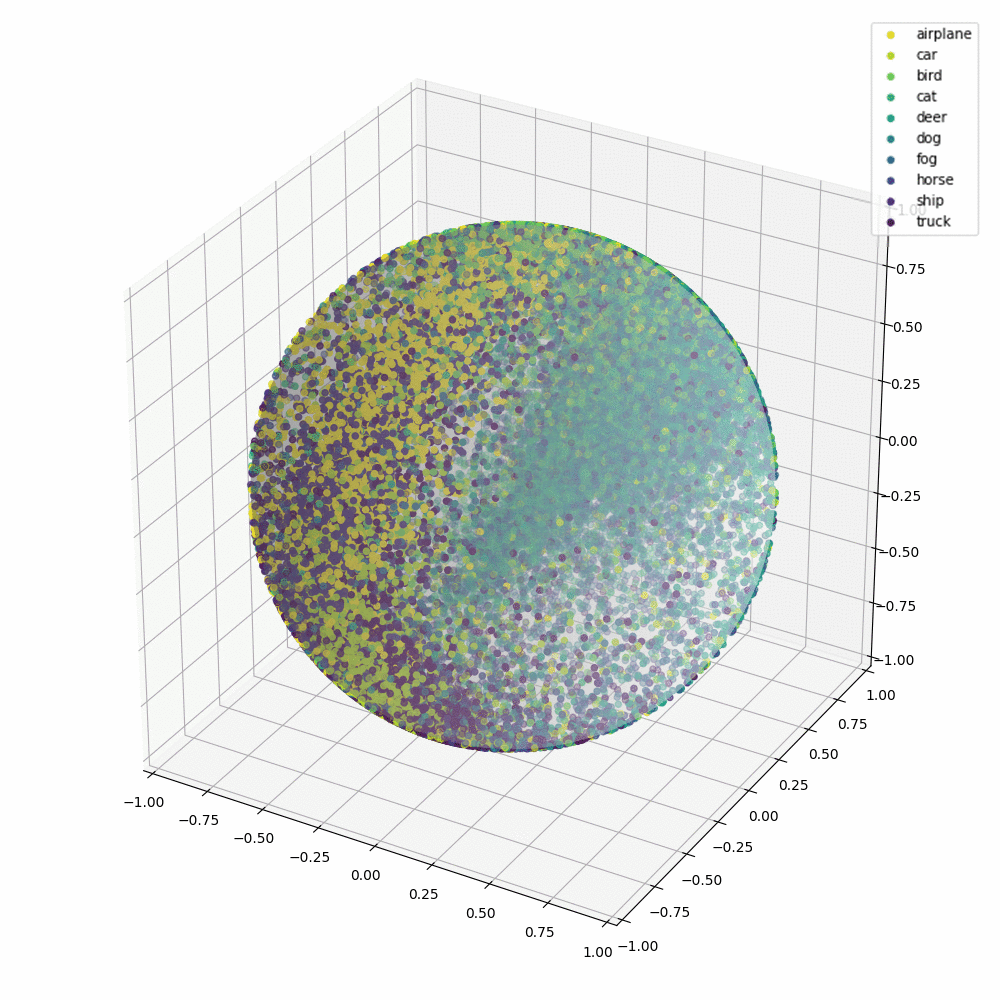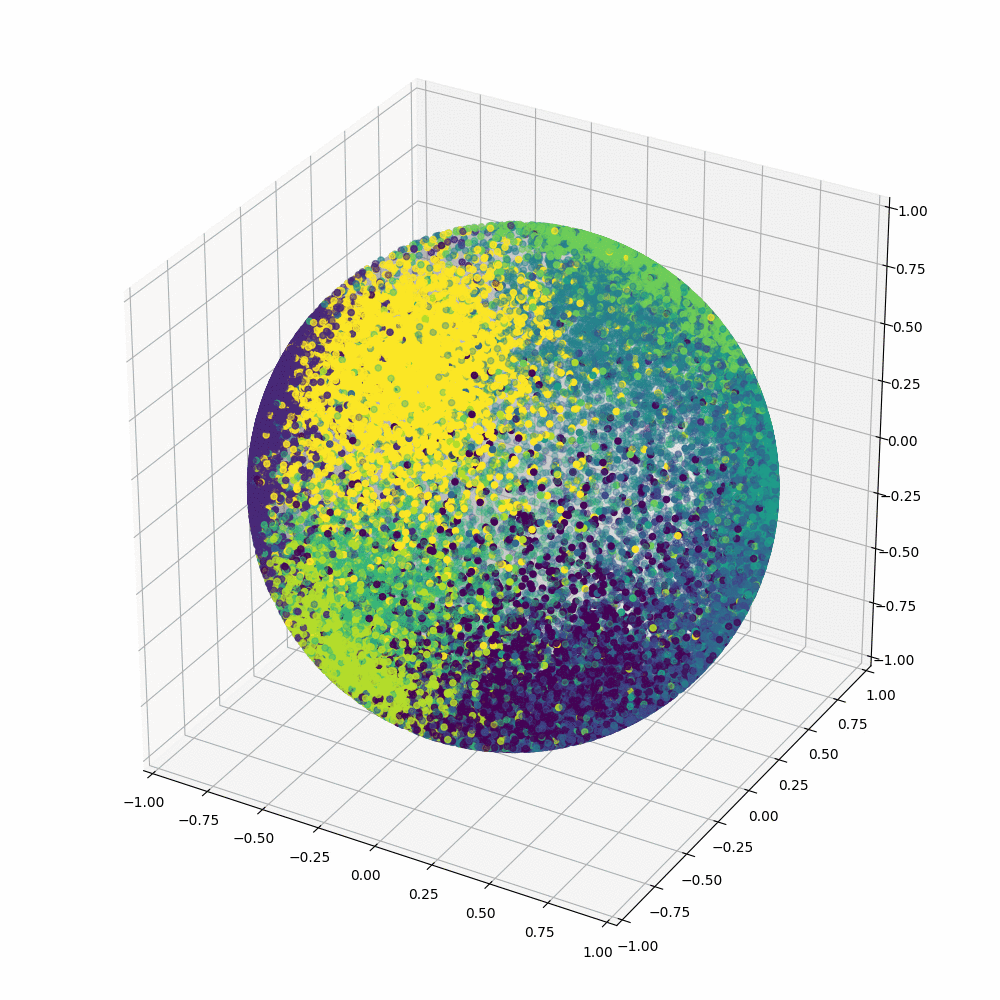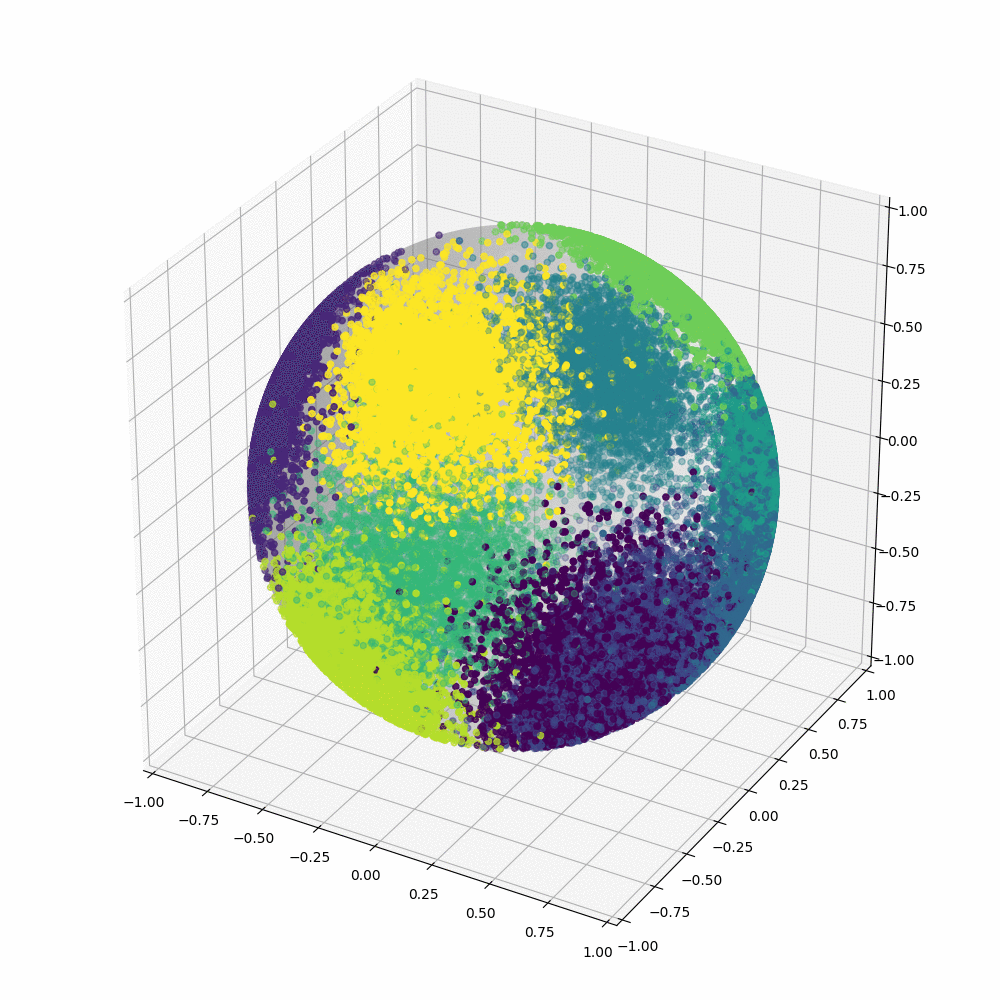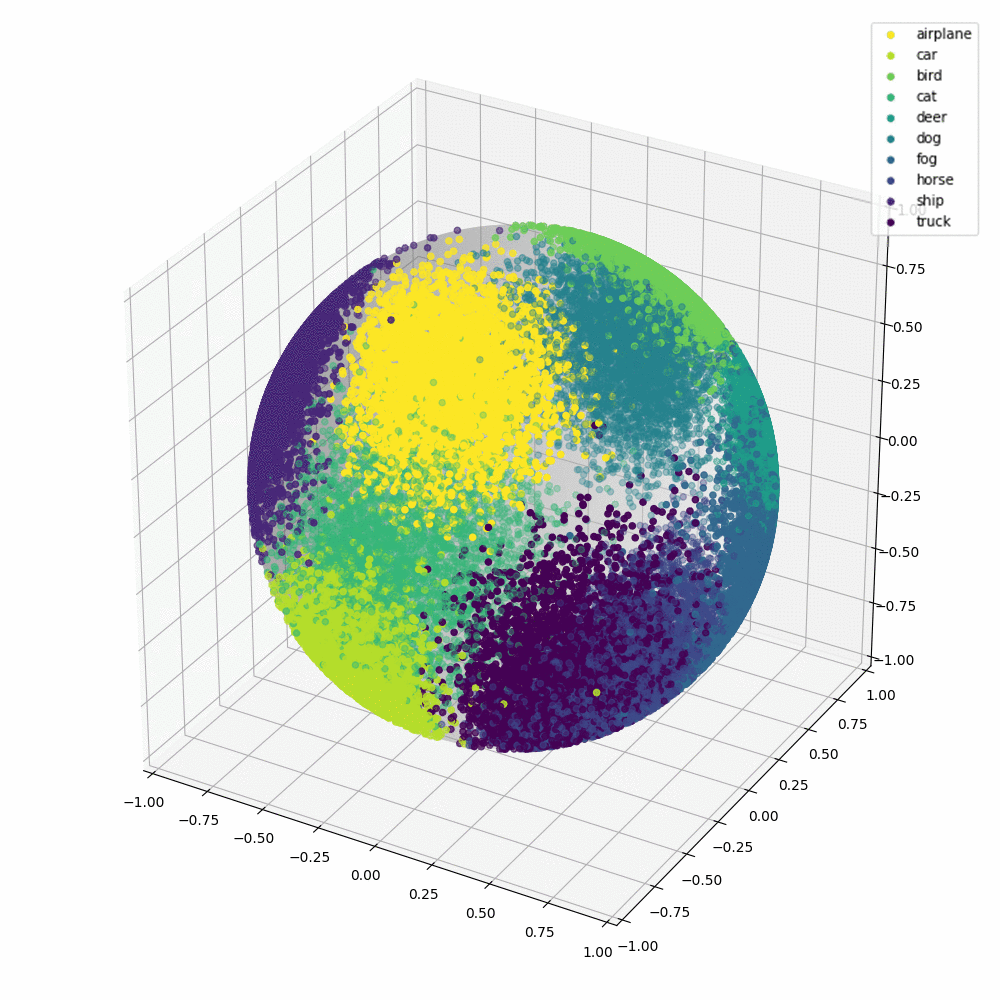
Future work:
Allow BN (gamma, beta)
to be learnt during stage two
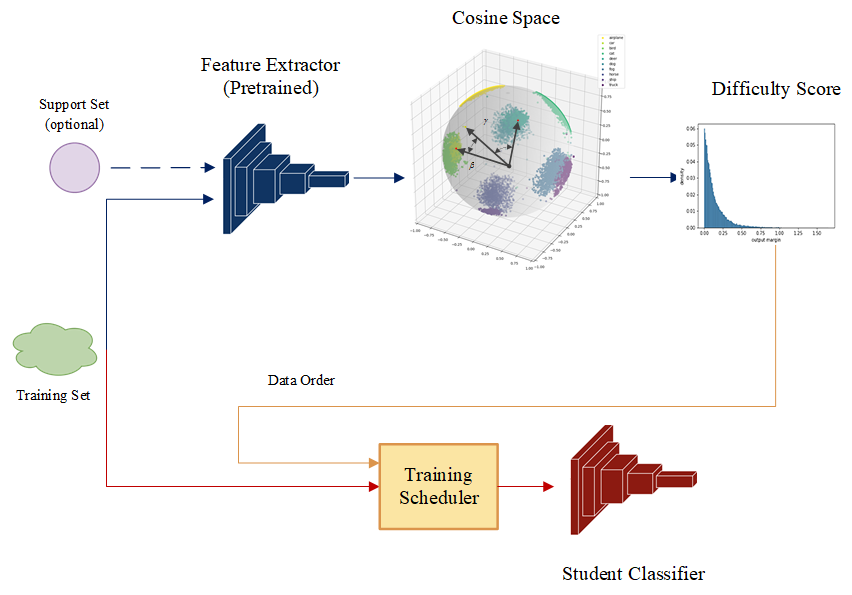
Stage two: Training a student : We freeze teacher's weights and evaluate difficulty scores. We reorder the input sequence with these scores
Part One: Difficulty metrics
Two stages for CL
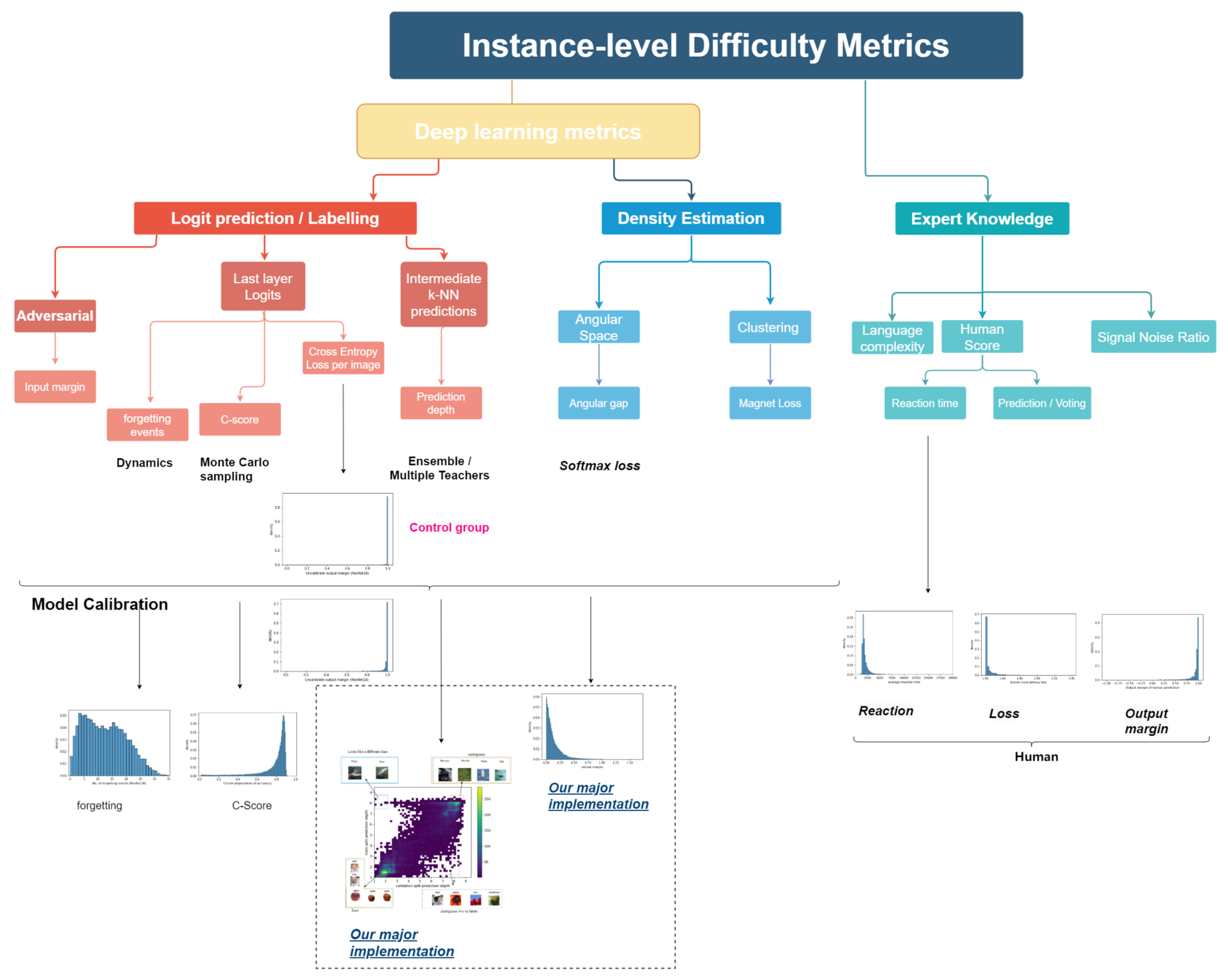
We compute the correlation between 9 difficulty scores.
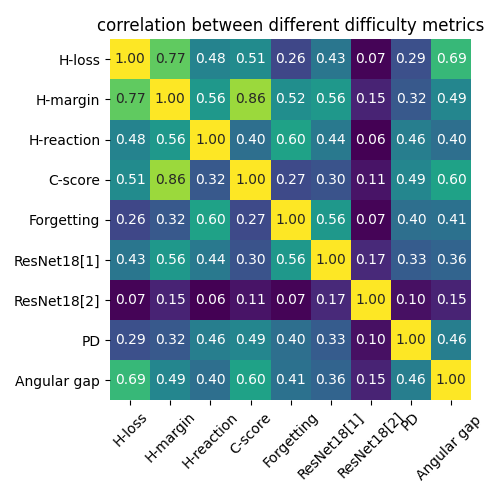
Footnotes:
H stands for human scores
ResNet18[1] is calibrated
ResNet18[2] is uncalibrated (control group)
Part1 Conclusion:
- Calibration is crucial for difficulty measurement
- Prediction depth is a novel metric
- Angular gap is highly interpretable
Part One: Difficulty metrics
Conclusion:
Part Two: Paced Learning methods
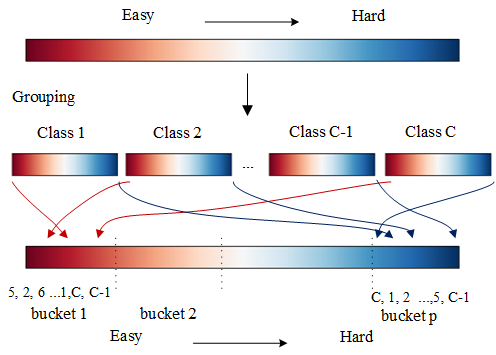
Our solution: Adding local randomness to the procomputed order with class balancing

Standard paced learning (PL) uses a fixed precomputed order
- Group samples with their labels from easy to hard
- Create class-balance data buckets

Problem: Unstable training
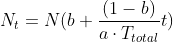
dict
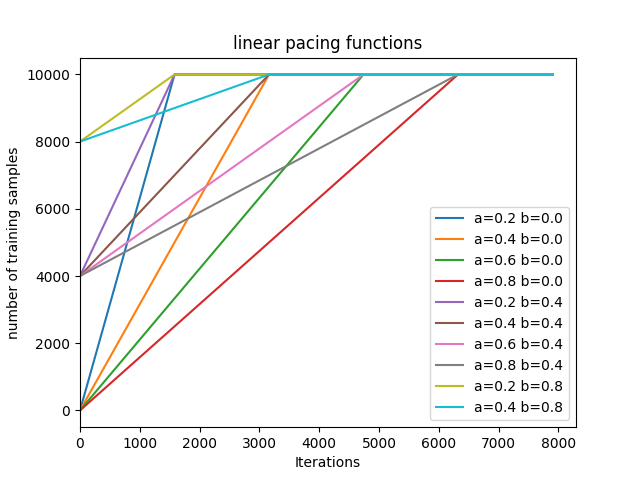
10 linear pacing functions
class-balance-aware scheduler
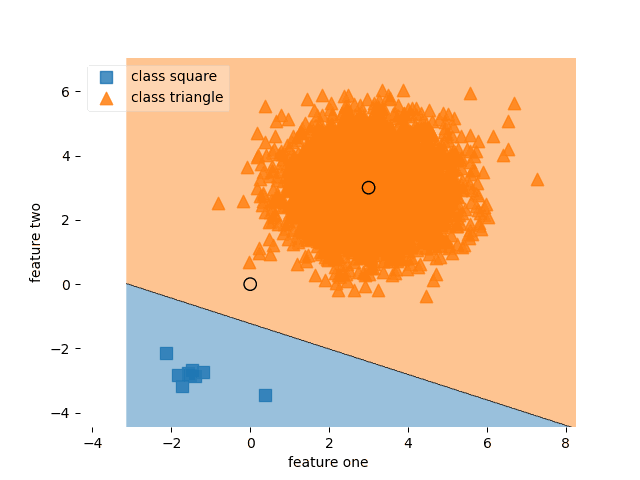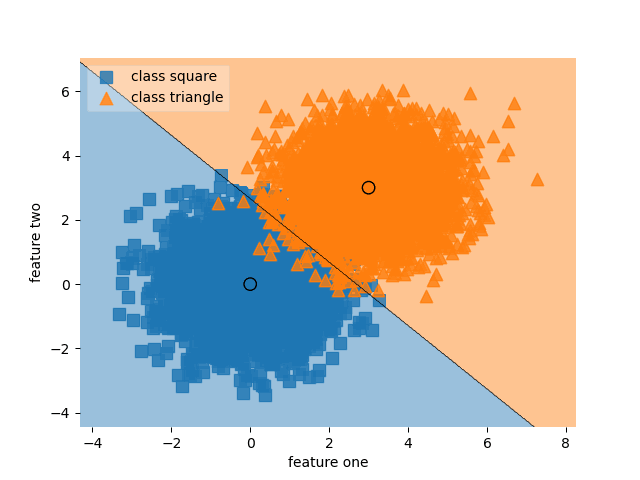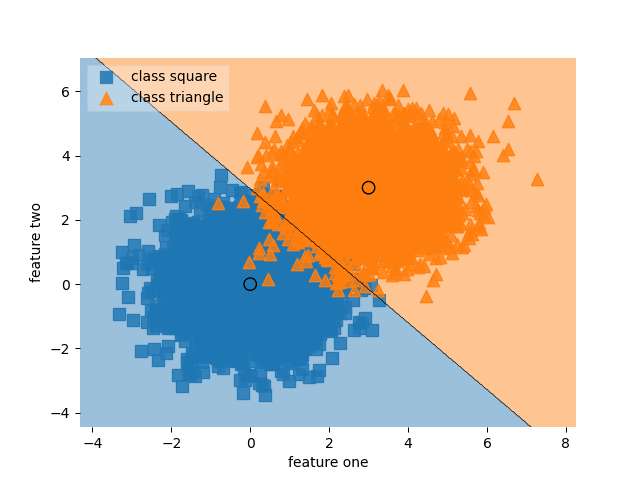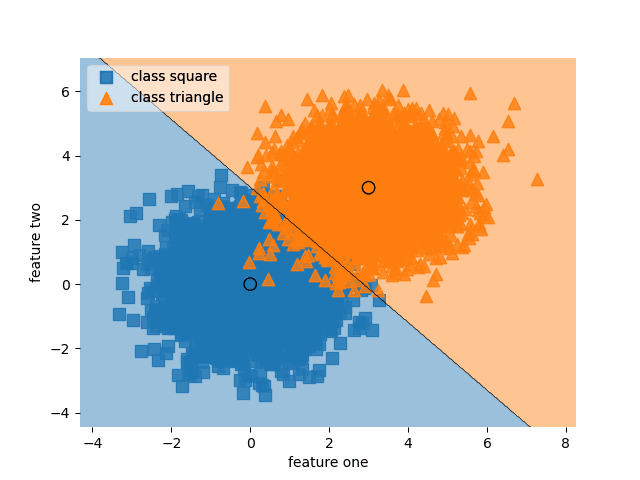
Self-paced learning (SPL) uses dynamic weights
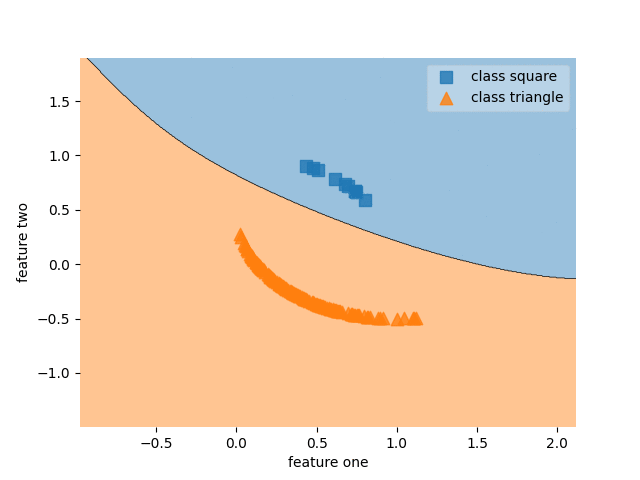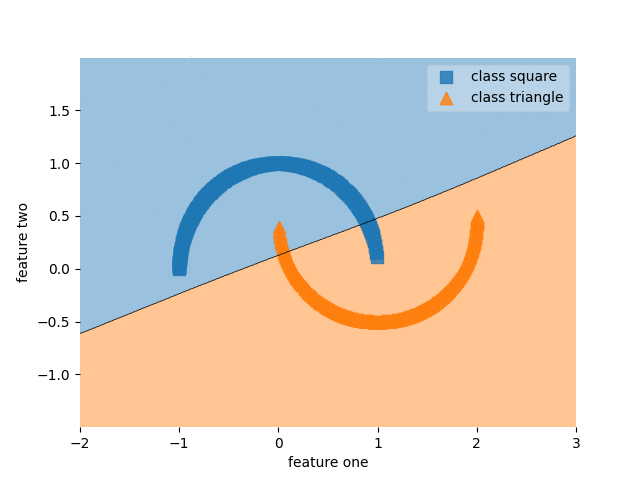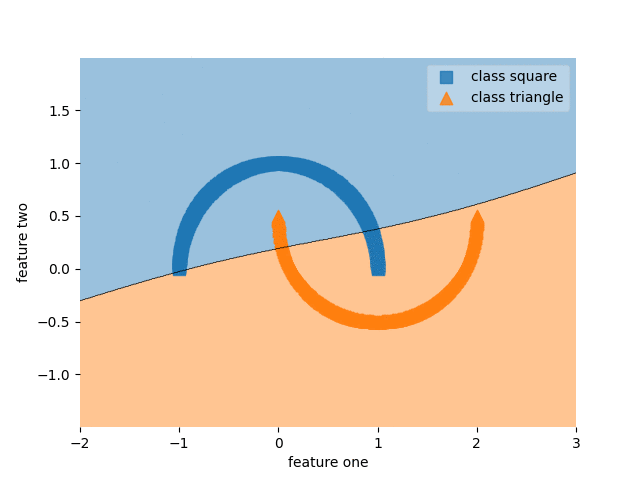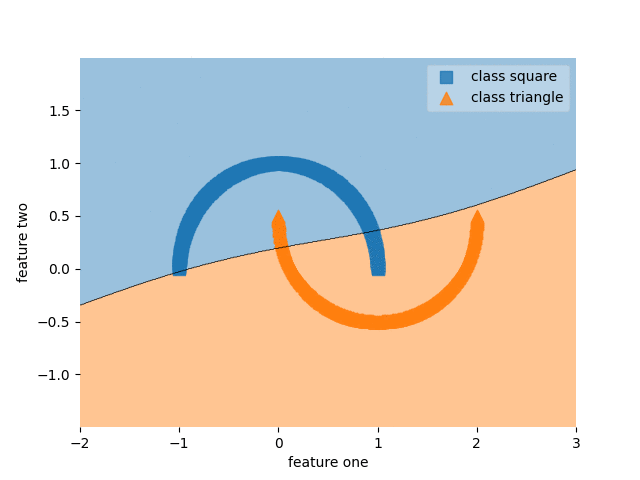
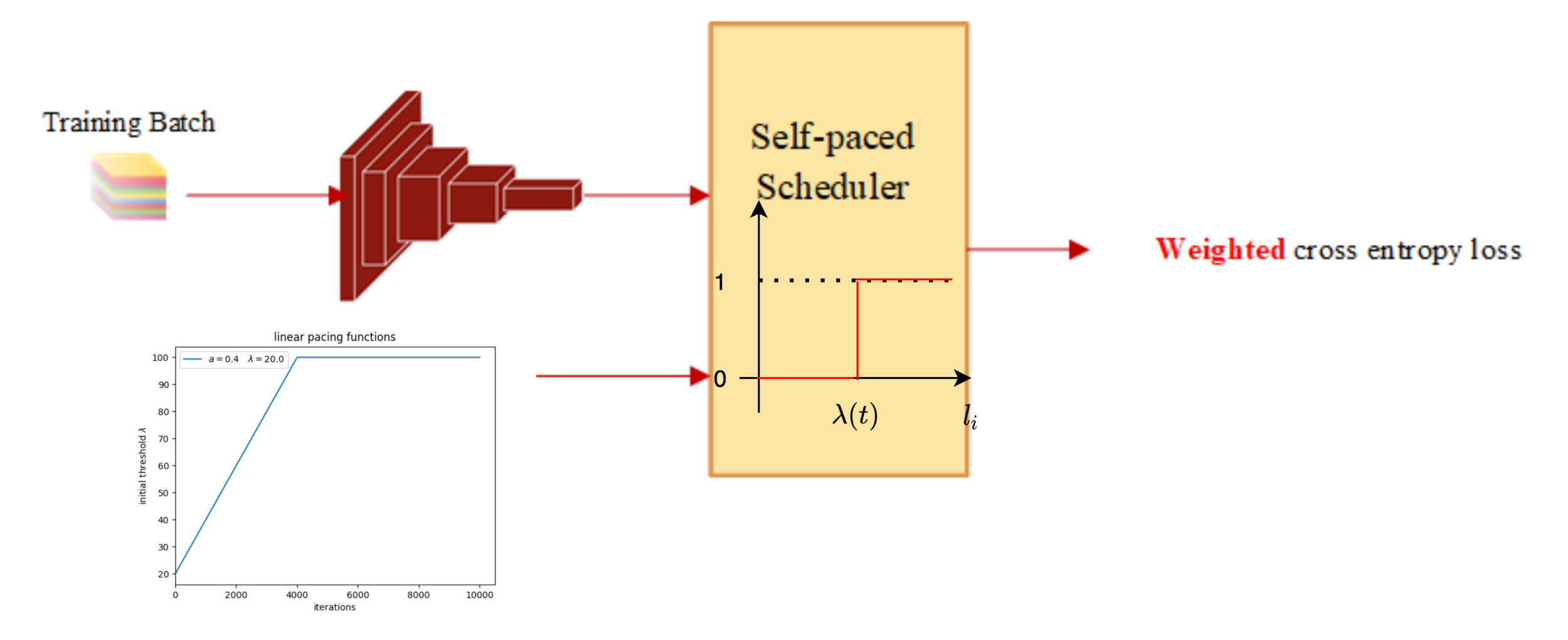
Part Two: Paced learning methods
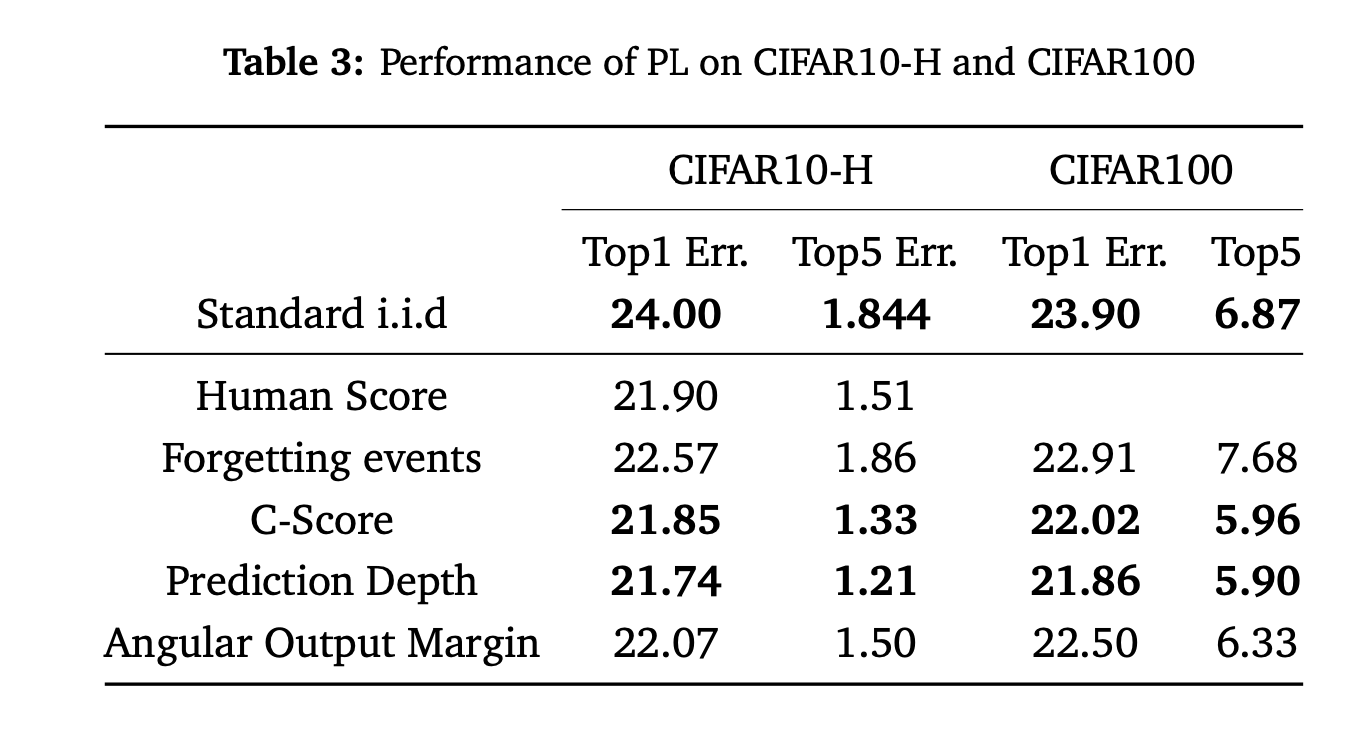
A linear classifier with SPL
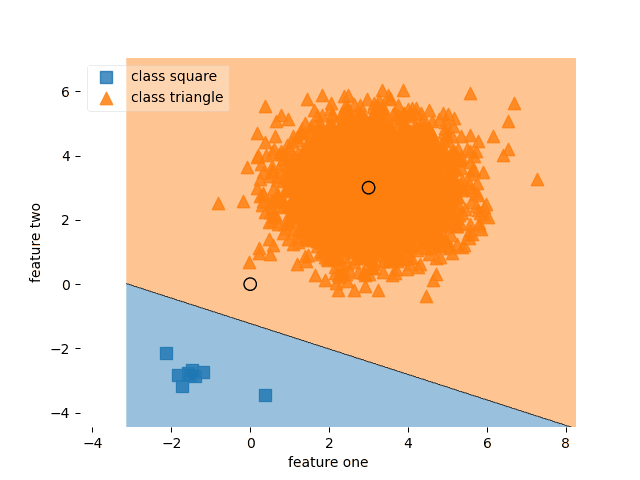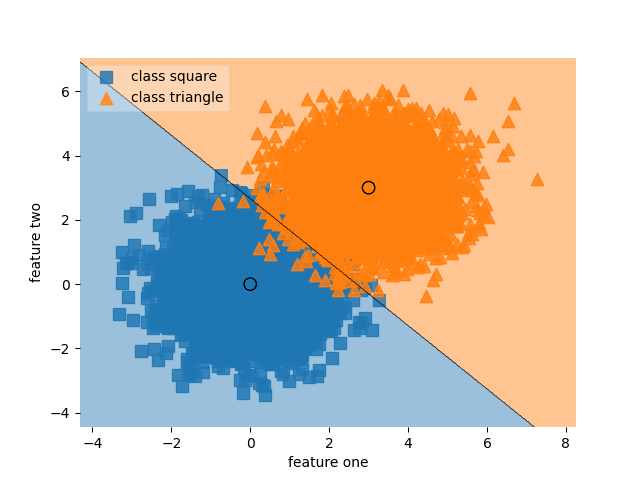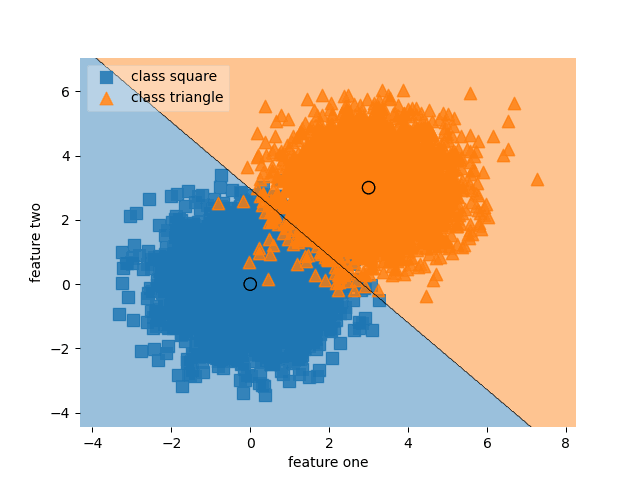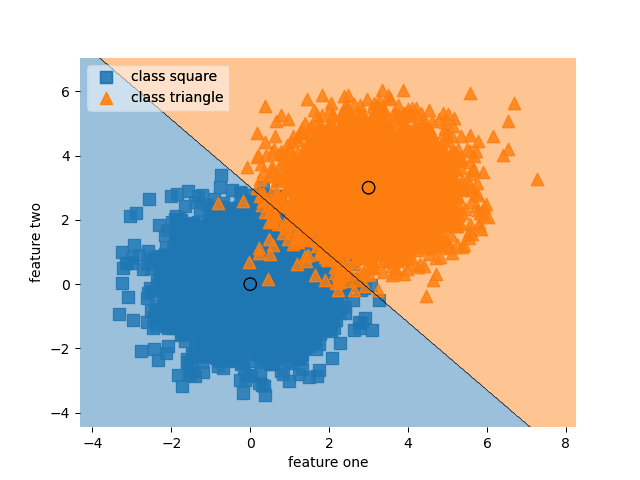
MLP with SPL
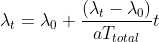
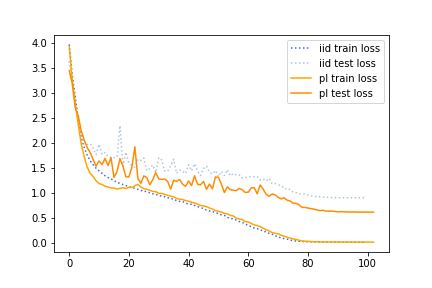
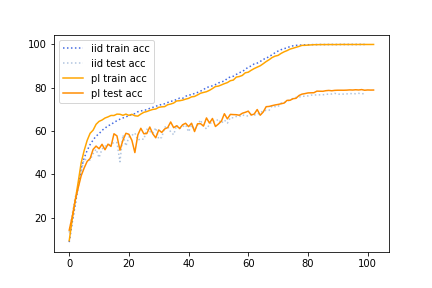
The difficulty scores measured by
unconverged DNN are very different
from pretrained teachers
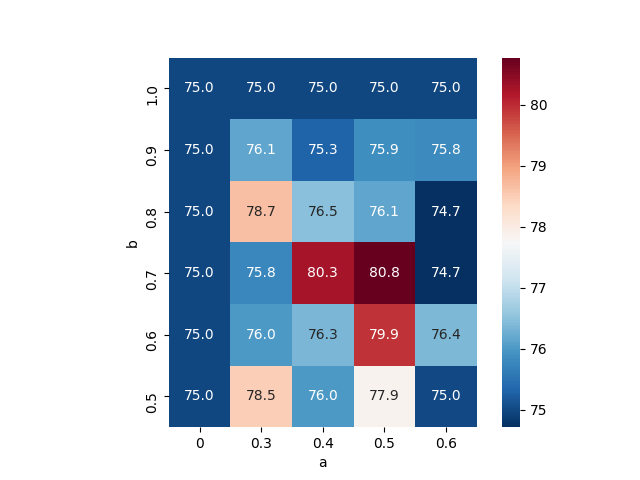
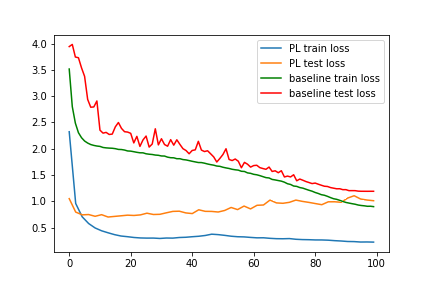
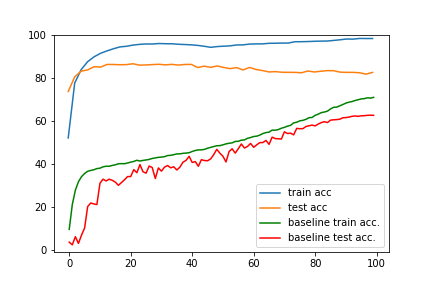
Ablation study of (PL methods) on CIFAR10-H
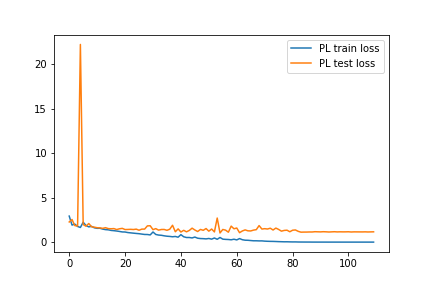
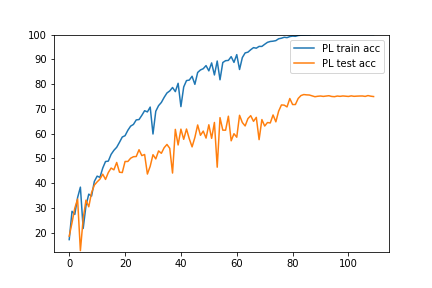
Standard paced learning can easily collapse during training
Part Two: Paced learning methods
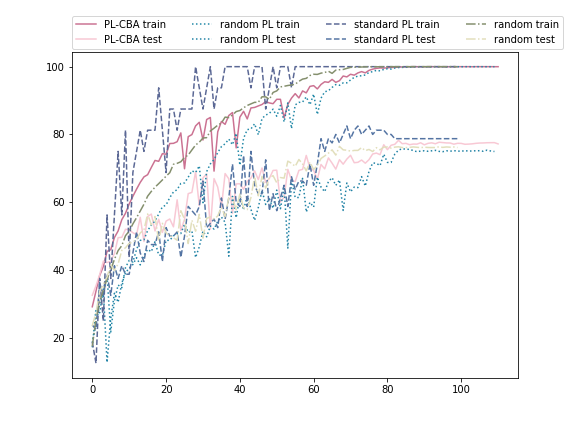
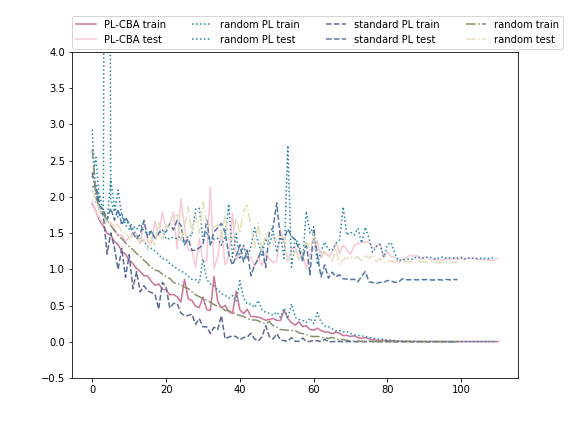
Accuracy
Loss
We train ResNet18 from scratch
with paced learning using our scheduler
Part Two: Paced learning methods
CL outperforms Adaptive Sharpness-aware Minimization (ASAM)
on test accuracy [8]
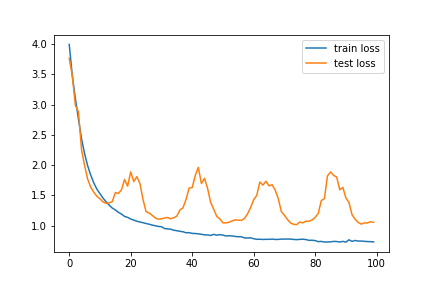
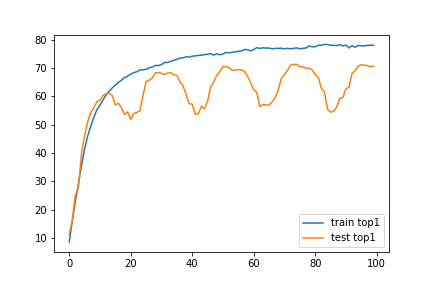
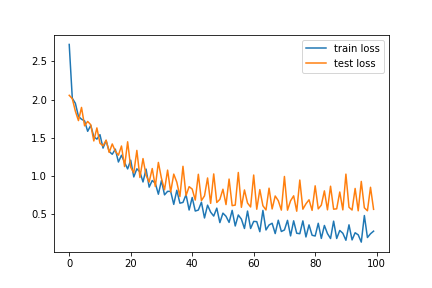
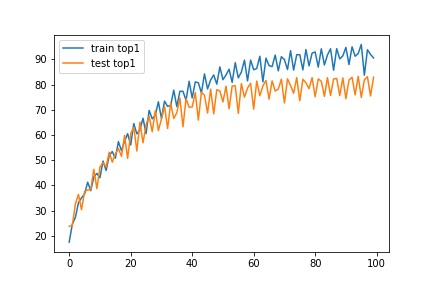
CIFAR10-H
CIFAR100
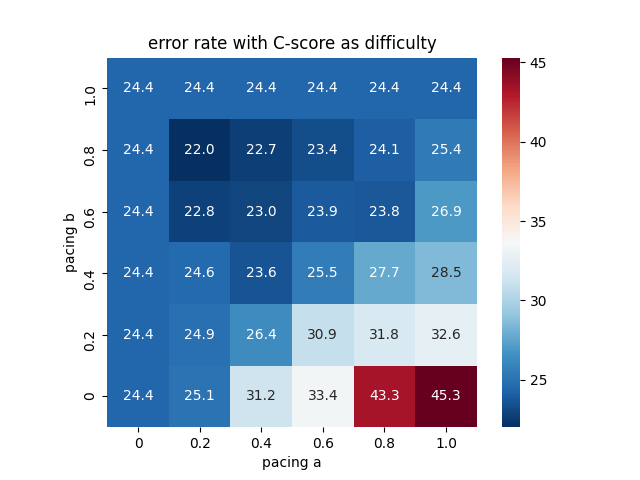
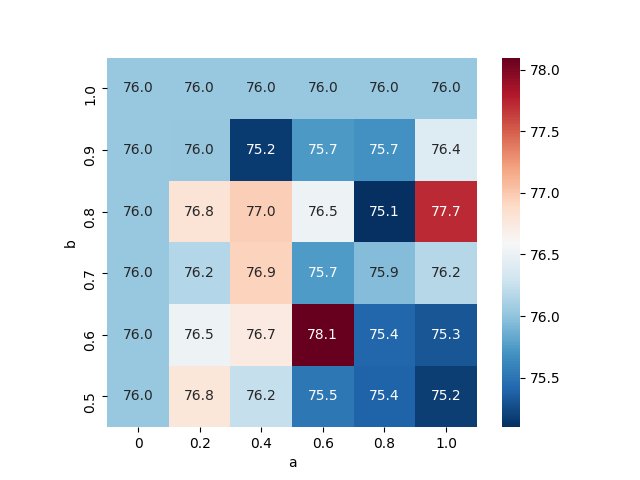
Results of paced learning with our CLA scheduler
CIFAR10-H
About 2%
CIFAR100
About 2%
For more search grids, please read our final report.
Part Two: Paced learning methods

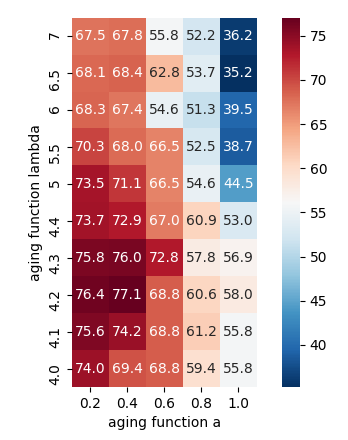
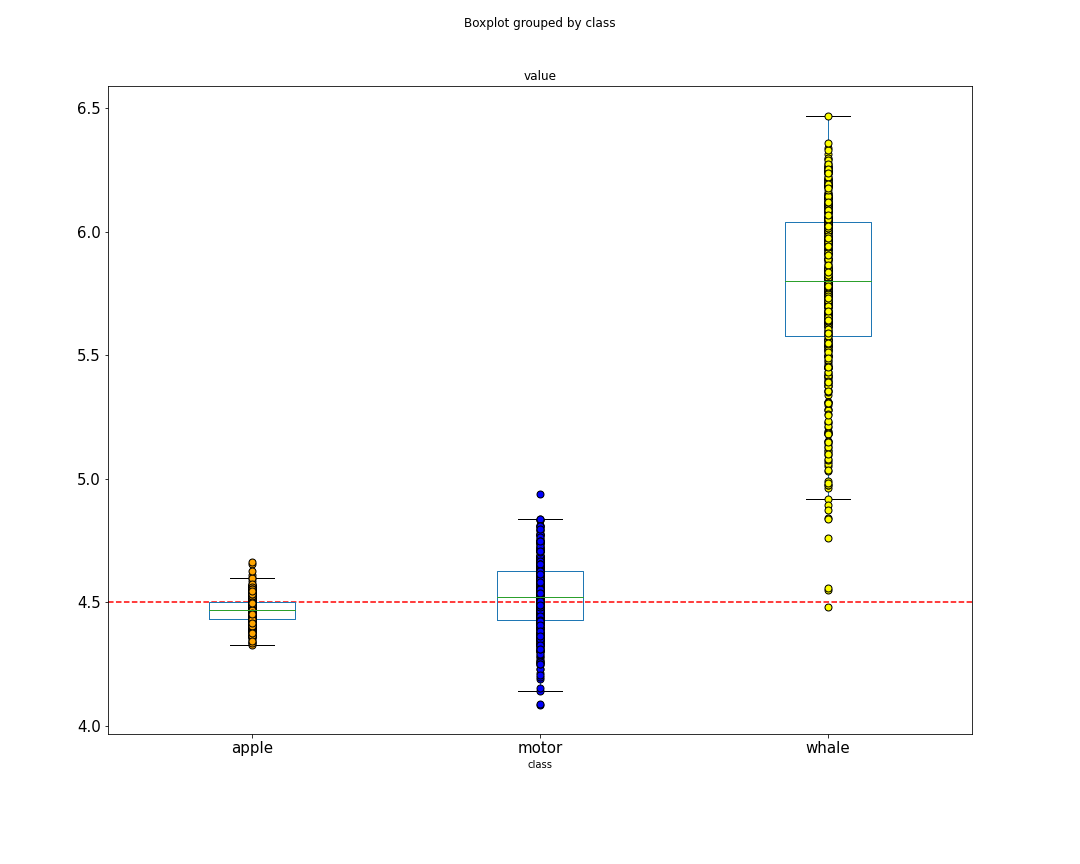
C-scores
Forgetting events
SPL cross entropy loss
(2nd epoch)
Does class imbalancing decrease test accuracy in SPL?
Can we improve SPL with model calibration?
Unsolved questions:
Difficulty scorese measured by unconverged DNNs are different
Comparing curriculum learning with different difficulty metrics
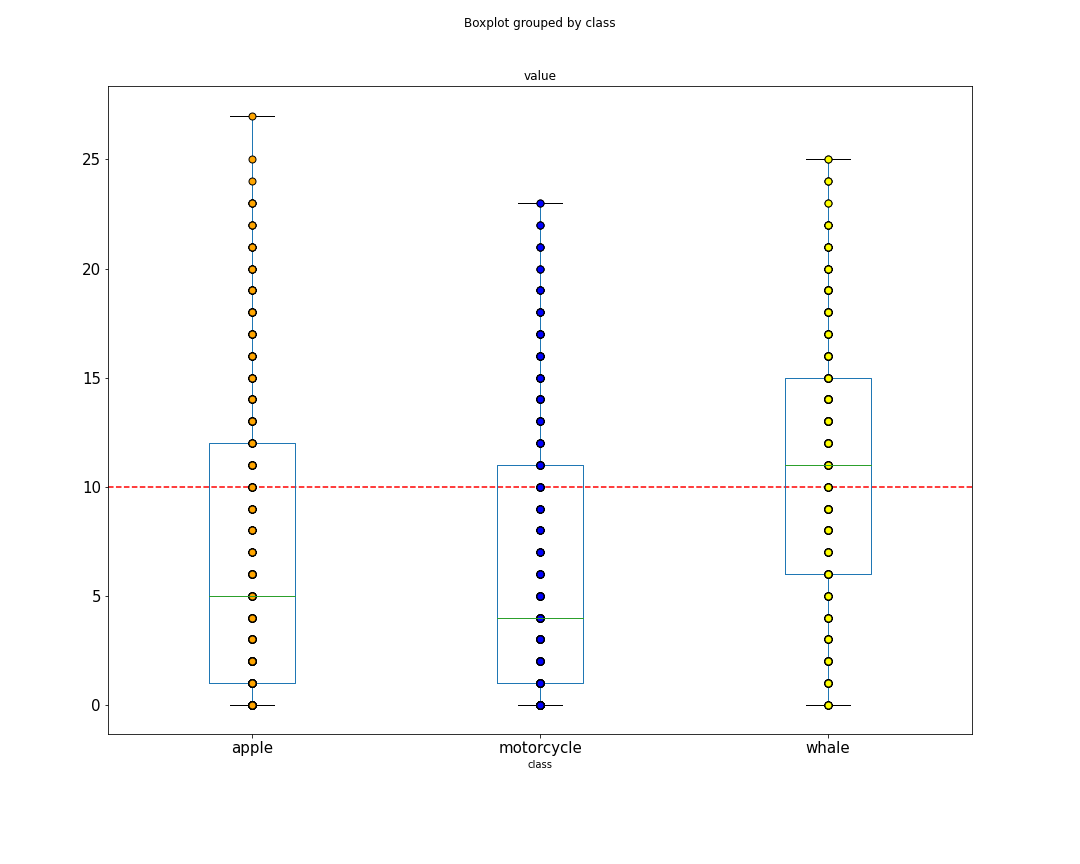
Transfer an EfficientNet B0 (SOTA) pretrained on ImageNet to CIFAR100
Training from easy to hard gives the pretrained model a better startup.
- Model calibration is crucial for difficulty measurement.
- Prediction depth detects fine-grained ambiguity and helps curriculum learning.
Future work
- Refine Prediction depth
- Combine angular gap with human in the loop (radius/ example position)
- Find theoretical support for class-balance-aware scheduler
-
Merge CL with knowledge distillation
Take-home messages:
- CL improves generalization for image classification.
- SPL is different from paced learning and learns in a class imbalanced way
Our main contributions
Part One:
- Perform curriculum learning with Prediction depth
- Propose an easy to interpret difficulty score
- Correlation analysis highlights the importance of model calibration
Part Two:
- Class-balance-aware paced learning scheduler
- Show CL's improvement for image classification
- Find Self-paced learning learns in class imbalance way
Reference:
[1] Yoshua Bengio, J. Louradour, Ronan Collobert, and J. Weston. Curriculum learning. 2009. pages 6, 19, 41
[2] Jerome S Bruner, Jacqueline J Goodnow, and George A Austin. A study of thinking. Rout- ledge, 2017. pages 5
[3] Robert JN Baldock, Hartmut Maennel, and Behnam Neyshabur. Deep learning through the lens of example difficulty. arXiv preprint arXiv:2106.09647, 2021. pages 13, 16, 27
[4] Hao Wang, Yitong Wang, Zheng Zhou, Xing Ji, Dihong Gong, Jingchao Zhou, Zhifeng Li, and Wei Liu. Cosface: Large margin cosine loss for deep face recognition, 2018. pages 35
[5] R. Battleday, Joshua C. Peterson, and T. Griffiths. Capturing human categorization of natural images by combining deep networks and cognitive models. Nature Communications, 11, 2020. pages 7, 8
[6] Mobarakol Islam and B. Glocker. Spatially varying label smoothing: Capturing uncertainty from expert annotations. In IPMI, 2021. pages 24
[7] Lu Jiang, Zhengyuan Zhou, Thomas Leung, L. Li, and Li Fei-Fei. Mentornet: Learning data- driven curriculum for very deep neural networks on corrupted labels. In ICML, 2018. pages 22
[8] Jungmin Kwon, Jeongseop Kim, Hyunseo Park, and In Kwon Choi. Asam: Adaptive sharpness-aware minimization for scale-invariant learning of deep neural networks, 2021. pages 53
Q&A